Optimizing Tool Selection for LLM Workflows: Differentiable Programming with PyTorch and DSPy
Update: Trended on Page 1 on HN for the whole weekend! Part 2 coming soon! Thanks for all the feedback. Hackernews discussion
How local, learnable routers can reduce token overhead, lower costs, and bring structure back to agentic workflows.
Modern agentic architectures rely heavily on chaining LLM calls. A typical pattern looks like:
- Use an LLM to decide which tool to invoke
- Call the tool (e.g. search, calculator, API)
- Use another LLM call to interpret the result and generate a final response
This structure is easy to reason about, simple to prototype, and generalizes well.
But it scales poorly.
Each LLM call incurs latency, cost, and token overhead. More subtly, it compounds context: every step includes not only the original query, but intermediate outputs and scratchpad logic from earlier prompts. This creates a growing burden on both inference and model performance.
The consequence is that most agent stacks are paying GPT-4 to do what amounts to classical control flow — tool selection — with no reuse, no abstraction, and no efficiency gains at scale.
The Alternative: Differentiable Routing
Instead of using an LLM to route between tools, we can model the decision as a trainable function. A differentiable controller learns tool selection from data — typically via reinforcement or supervised fine-tuning — and runs entirely outside the LLM.
The benefits are architectural:
- Local execution — avoids external API calls
- Determinism — removes stochastic sampling from routing
- Composability — integrates natively with PyTorch / DSPy pipelines
- Control — tool choice is explainable and debuggable
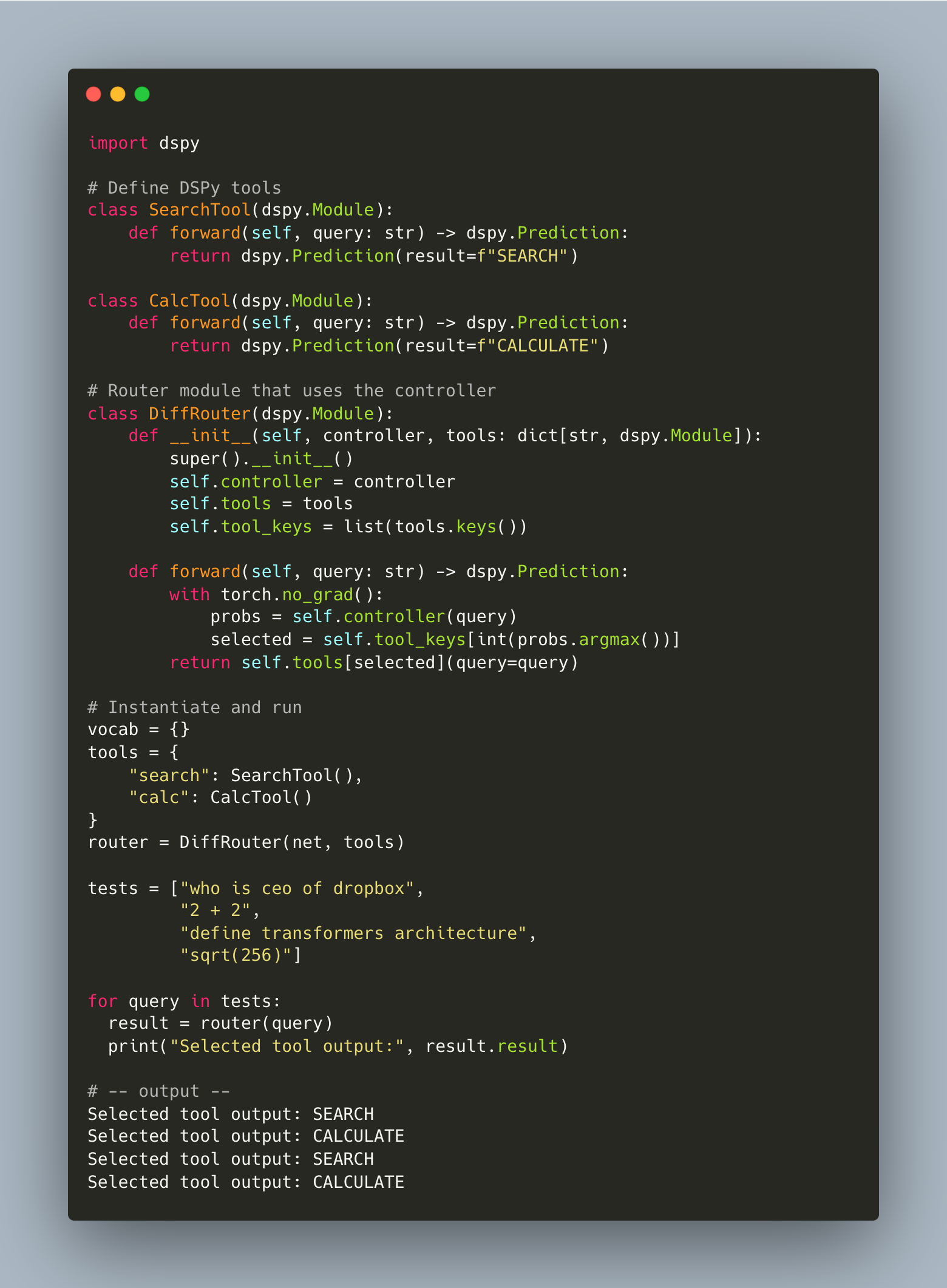
A minimal examples looks like this (PyTorch):
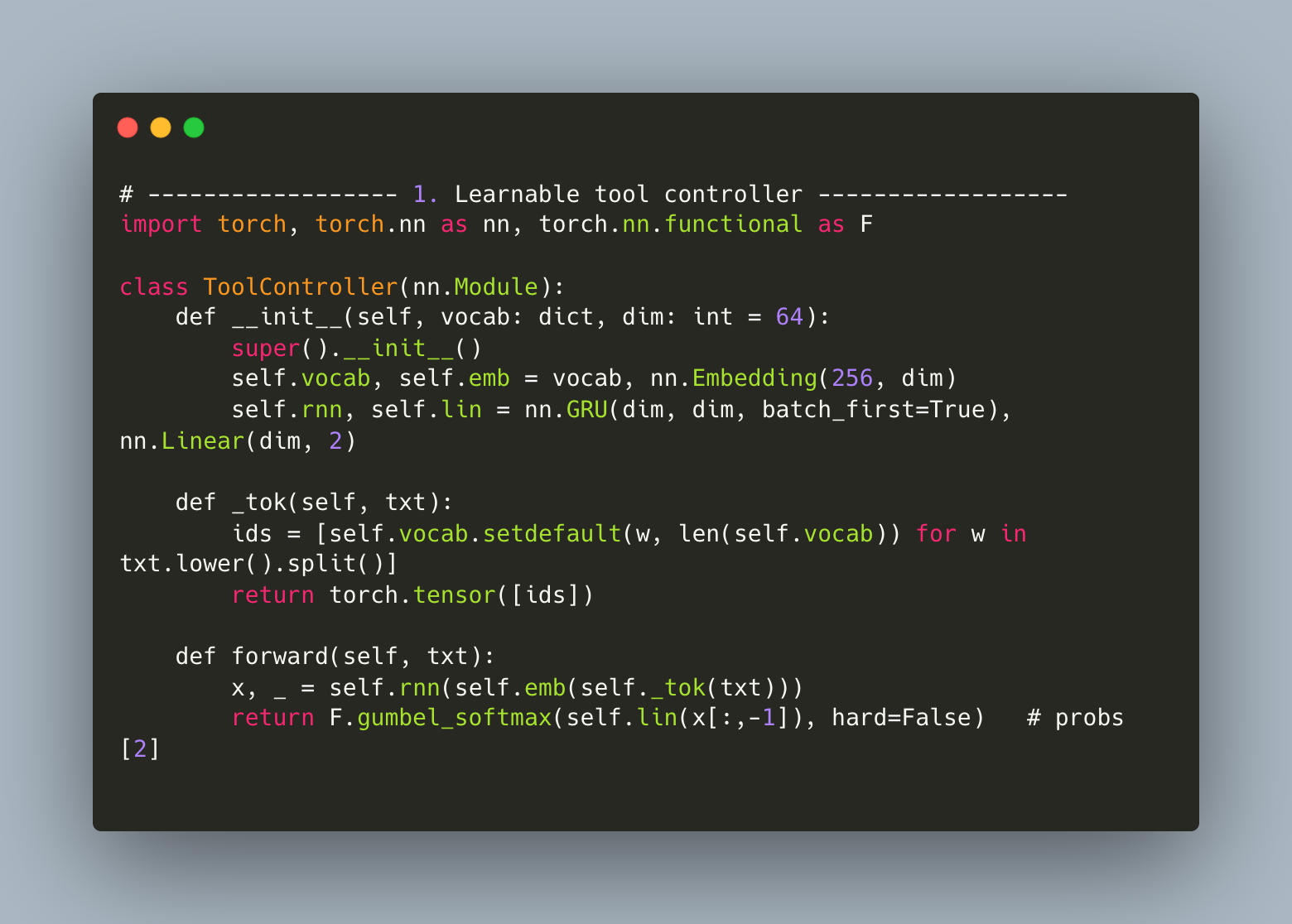
This is a simple 4-layer network: input is tokenized text; output is a softmax distribution over tools. Because it’s differentiable, you can backpropagate from downstream task reward and improve the router over time.
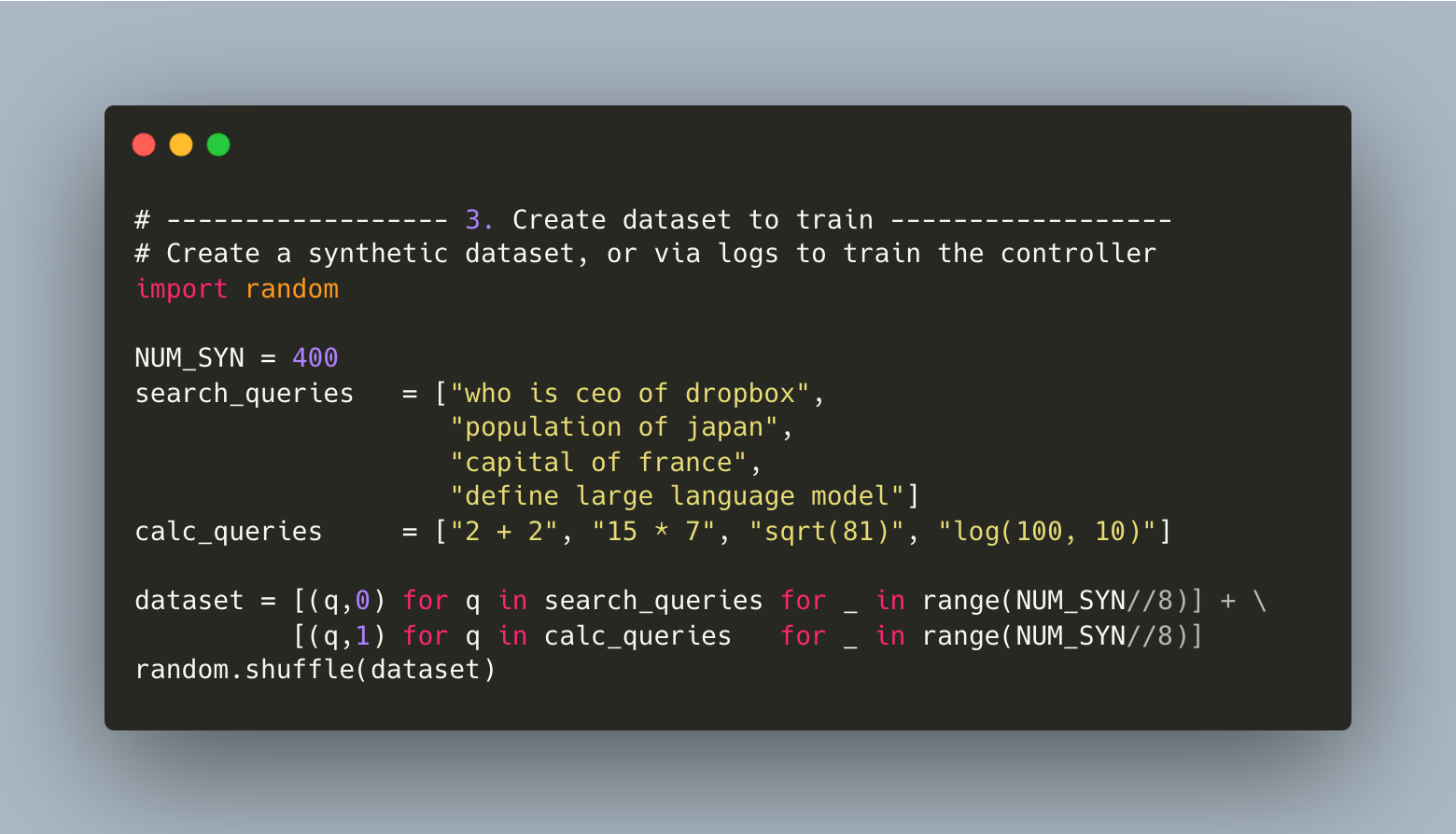
We can either get data from existing logs, or use GPT to create a synthetic dataset. (Our costs will be one time per tool controller, vs LLM calls for them in production).
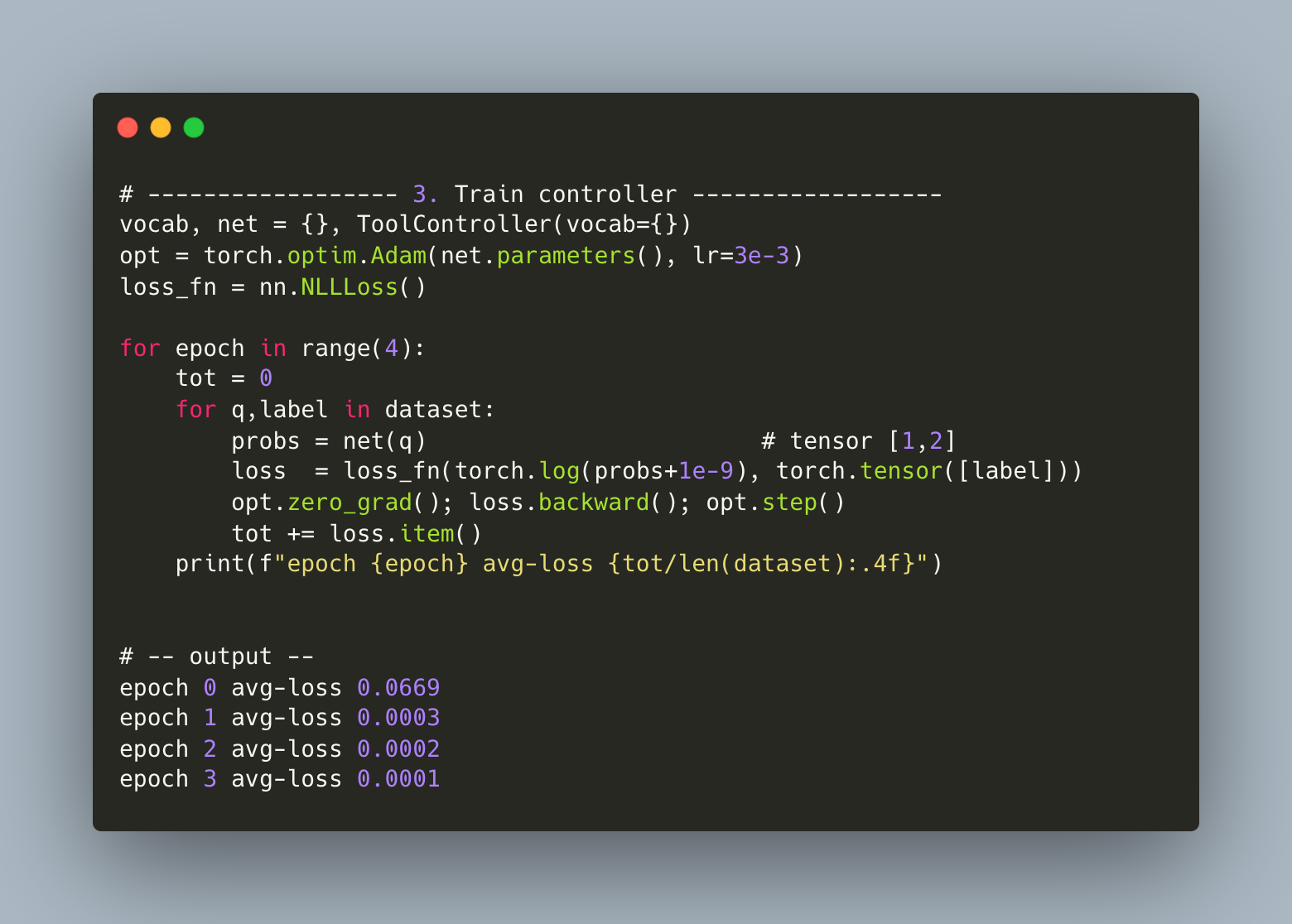
We use a simple Adam optimizer to train this simple controller.

And finally, the demo!
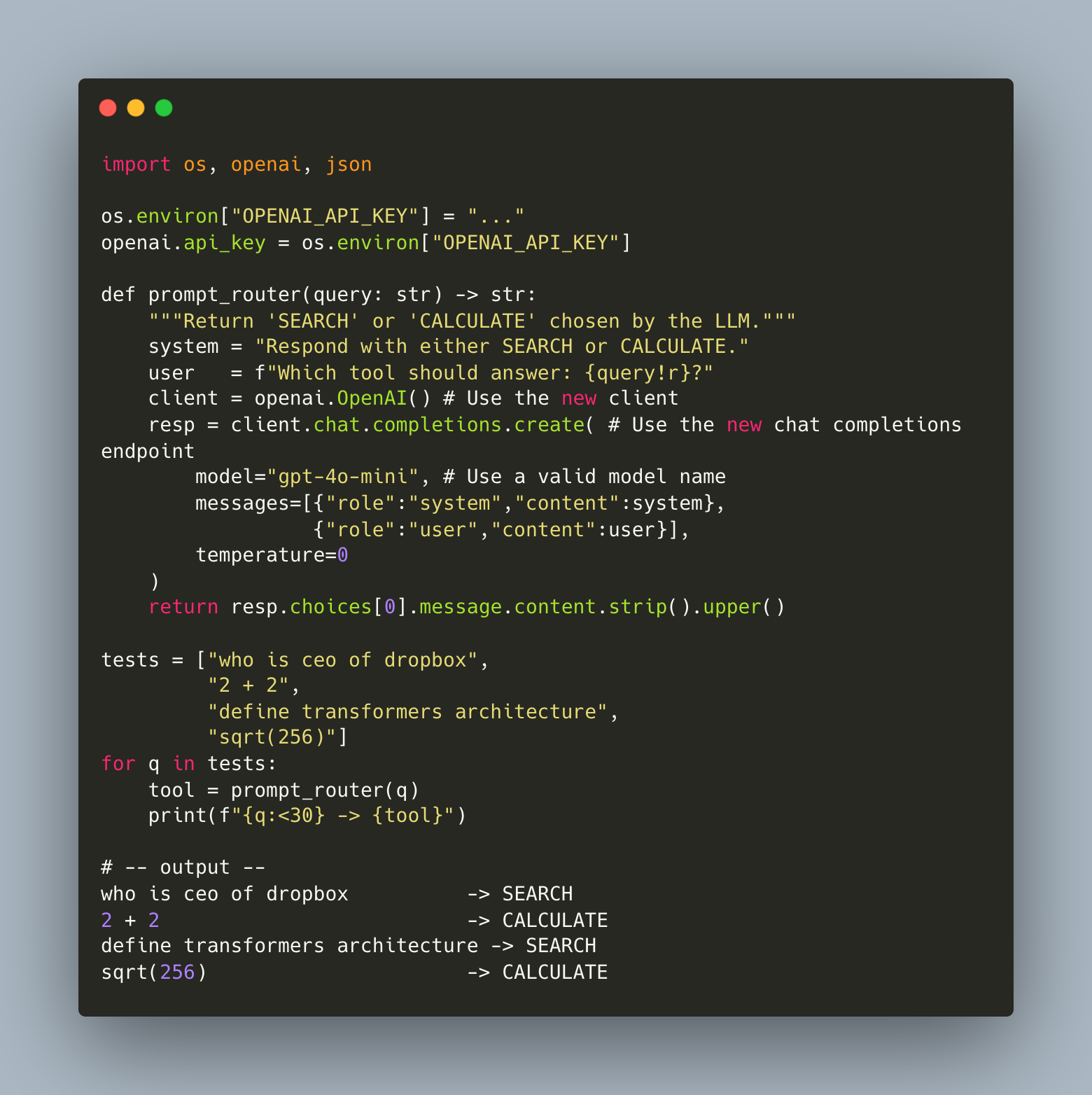
For completeness, this is how we’d do it via an LLM directly.
And as a bonus, here’s how you would integrate it into a DSPy Pipeline.
Context Growth and Model Degradation
Prompt-based planners incur a hidden penalty: context inflation.
Each new prompt must reintroduce the full conversation history, prior decisions, and any scratch output. The result is exponential growth in irrelevant tokens, particularly in multi-hop workflows.
This leads to:
- Token tax — redundant tokens sent repeatedly
- Truncation risk — long contexts hit model limits earlier
- Attention dilution — more tokens competing for limited compute
- Leakage — planner logic unintentionally affects final output
By contrast, a differentiable router operates entirely out-of-band. The only input to the final LLM call is the original query and the selected tool’s result. Context length is constant regardless of tool depth.

This architectural separation restores clarity to the final model call — reducing hallucinations, improving determinism, and reclaiming inference capacity for core reasoning.
Strategic Implications
The shift to differentiable routing mirrors a broader trend:
Separating declarative control logic from generative inference.
Current agentic systems blur this line. Tool selection is handled in the same modality — and often the same model — as natural language generation. This creates coupling where there should be composition.
Differentiable programming is one way to decouple the two:
- LLMs focus on generation and synthesis
- Lightweight neural modules handle routing, orchestration, and control
The result is a more modular, inspectable, and scalable architecture — one that avoids paying transformer inference costs for classical programming constructs.
Prompt Routing and Its Costs
To drive this home, lets consider a planner that routes queries between a search API and a calculator tool. Each query invokes:
- One LLM call to plan
- One LLM call to interpret the tool’s result
- One LLM call to generate the final answer
At GPT-4.1 prices (75 input / 75 output tokens per call), this costs:

A 3× reduction in cost per run — with larger savings as tool chains grow in complexity.
Conclusion
In early-stage workflows, LLM routing is fast to implement and flexible to extend. But at scale, it’s structurally inefficient — economically and architecturally.
Differentiable controllers offer an excellent alternative. They reduce cost, improve performance, and clarify model behavior. They mark a step toward LLM systems that look less like prompt chains — and more like programs.
--
--
Questions or feedback? @viksit on Twitter.
From Prompts to Programs: Why We Need a Compiler for LLMs
Early computing started with logic gates. We wrote in binary because we could reason about how bits flowed through circuits. As complexity grew, we invented assembly languages to abstract over machine code: still low-level, but easier to manage. Eventually we built high-level languages like C that let us describe intent, not instruction sequences.
Each jump in abstraction made us more productive. It let us build larger, more reliable systems without needing to hold every gate or register in our head.
We’re hitting the same point in LLM development.
LLMs today are logic gates — powerful, expressive, and composable. Prompts are our binary. You can wire together a few models, handcraft their inputs and outputs, and get something useful. But once you go beyond a handful of prompts — say, in agent systems, retrieval pipelines, evaluation layers — the complexity gets out of hand. It’s like writing an OS in raw assembly.
We need to move up the stack.
That’s what Selvedge is for: a compiler for LLM workflows. It’s a typed, declarative way to describe what you want, and a system that figures out how to make it happen.
Selvedge lets you define structured programs that wrap model calls, validate outputs, compose reasoning steps, and orchestrate everything with explicit control flow. The primitives are predictable. The types are enforced. The intermediate states are inspectable. It turns prompt soup into programs you can debug. The best part is — you barely write prompts.

Think of it like:
- C for LLMs: you define the logic, not the token stream
- SQL for cognition: you declare what you want, not how to traverse the model
We don’t think in prompts. We think in goals, logic, and flow. And the systems we’re building now — agents, copilots, assistants, autonomous processes — deserve tooling that reflects that.
Selvedge is an early step in that direction. A compiler for intent.
A language for AI native programs, not just prompts.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Three Futures for AI
We’re racing toward something. Whether it’s AGI or another false summit, the scale of what we’re building is hard to ignore.
There are only a few ways this plays out.
1. We scale current techniques to AGI.
The compute, energy, and coordination required are beyond any single country. power grids the size of Brazil, cooling towers louder than waterfalls. It becomes clear that no one country can do it alone. So we’re faced with a choice.
Do we come together and build it, or fight until one of us claims it for ourselves?
2. We invent a breakthrough.
Not scale. Just one singular leap out of a lab or a company or a garage. A chip, a model, a cooling trick. Suddenly, the gap between “close” and “there” disappears. Someone gets there first.
Do they share it? Or defend it like a weapon?
3. LLMs plateau.
They change everything, but stop short of general intelligence. We chase margins. Optimize workflows. The systems get smarter, but not general. Eventually the hype fades. Not because AI failed but because it settled into the tedium of obviousness.
A winter, not of research, but of imagination.
Two of these futures end in conflict. One in exhaustion. Only one asks us to act like a species.
We may not control what we discover. But we will decide how we respond.
I hope we choose well.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
When Software Starts To Listen
Most software today is basically deaf. You poke at it, and if you’re lucky, it does what you want. But it doesn’t listen. Not really. That’s about to change.
Say your product’s ad campaign just blew up. The VP wants a buy‑3‑get‑1‑free promotion online in the next ten minutes. In most companies, this would kick off a chain of escalation: tickets, grooming, prioritization, maybe a hotfix sprint. Everyone stressed. Nobody moving fast enough.
But imagine a different setup. You open a file called pricing.spec and type:
## flash_promo_may6_2025
if cart_items >= 4:
discount cheapest_item 100%
You hit publish. The storefront updates. You go back to your coffee.
This isn’t magic. It’s just what happens when the boundary between “spec” and “software” disappears. You stop writing instructions for other humans to implement, and start writing directly for the system.
That’s what I mean by software that listens.
It won’t show up everywhere at once. It’ll sneak in at the edges — inside bounded platforms that already own the stack. Salesforce. Shopify. Figma. Tools where the system already knows the schema, the constraints, the deploy surface. Once a model is embedded in that loop, a lot of the glue work goes away. The scaffolding becomes active.
You won’t need someone to translate what you want into what the machine can do. The machine will learn to speak human. And this breaks the org chart in interesting ways.
In the current world, building software is a game of telephone between PMs, engineers, and designers. Everyone has their domain, and communication is the hard part. But if the system listens — if it really listens — then you don’t need as many people repeating themselves.
You’re either:
- building with AI (apps),
- building AI itself (models), or
- building for AI (infra, safety, tooling).
That’s it. Everything else starts to look like overhead.
Jamie Zawinski once said every program grows until it can read email.
I’d guess that now, every serious app grows until it can read your mind.
We already see early versions of this: autocomplete, command palettes, prompt UIs. But the real magic happens when software predicts your intent before you articulate it. Not just filling in blanks — actually shaping the interface to fit your next move.
That’s coming. And when it does, the way we build things will start to invert.
Most people won’t notice at first. Architects will keep using their old CAD tools. Accountants will keep using Excel. Editors will keep using the timeline. But behind the scenes, those tools will start responding to natural language. They’ll adapt on the fly. They’ll let users patch over missing or new functionality without plugins or workarounds or other developers.
This is Excel macros for everything.
Except instead of writing brittle scripts, you’re just describing what you want — and the system figures out how to do it. Long-tail functionality stops being something you beg the vendor for. It becomes something you compose.
So where does that leave product managers? They don’t go away. But their work shifts up a level. They’re not writing tickets. They’re deciding,
- What the model should expose.
- What it should hide.
- What’s safe to extend.
- What breaks if someone gets too clever.
They define the primitives, set the defaults, and watch the feedback loops. Every model embedded in a product becomes a kind of UX researcher — logging friction, clustering hacks, surfacing gaps in capability.
Product becomes less about what gets built, and more about what can be built.
There are risks, of course. When software listens, it can also mishear. A stray prompt can mutate a database. A rogue extension can leak sensitive logic.
An LLM with too much power and not enough guardrails can wreck things in ways you won’t catch until it’s too late. This is where product and infra start to blur. Versioning, access control, audit trails — they’re not just technical features. They’re product decisions now. Governance becomes part of the interface.
The main thing to understand is this:
Software that listens collapses the distance between wanting and working**.**
Today, we build tools that people learn to use. Tomorrow, we’ll build systems that learn how people want to work.
And once that happens, the most valuable people in the loop will be the ones who can express intent clearly — and the ones who can shape how the system responds. If you’re not doing one of those two things, you’ll have to explain why you’re still in the room.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Prompt Engineering Is the New Assembly Language
There’s a belief circulating in AI circles right now that a cleverly written prompt is proprietary gold. That if you can coax the right output from a model, you’ve created something defensible.
I get the instinct. When something works, and nobody else seems to have figured it out yet, it feels like IP. But that feeling won’t last. Not because prompts aren’t useful, but because they’re legible, replicable, and quite disposable.
Prompts at their core are specs. They describe what you want a model to do, given a certain input and output shape. You write them in English, wire them into some UX or tooling, and if you’re lucky, the system does what you hoped it would.
But we’ve seen this pattern before. Every generation of software development starts with hand-tuned instructions, then moves toward abstraction and automation.
First, we wrote in binary. Then came assembly. Then C. Then Python. We built compilers and interpreters that took your vague intent and optimized it into something performant.
We’re about to hit the same inflection point with LLMs.
Tools like DSPy are already acting like early compilers, taking high-level intent and generating prompt graphs, optimizing them over time. With Selvedge, I’ve been exploring what it means to treat prompts not as text but as composable programs. Structured, typed, and abstracted from the model itself. The system handles the orchestration — which model, which format, which chain — based on the spec.
This is where prompts as a moat break down. If the compiler is doing the hard work, the prompt itself isn’t the moat. It’s a temporary interface, a layer that’ll be rewritten, tuned, or discarded automatically based on what the developer wants to do.
So what actually compounds?
Usage. Feedback loops. Distribution. You build defensibility by owning the layer where users express intent — not the syntax of that expression. The edge won’t come from the prompt itself, but from the infrastructure that improves with every interaction.
We’re moving from being prompt authors to becoming compiler designers. From crafting clever phrasing to building systems that know how to reason backward from a goal. The moat, then, isn’t the instruction at all. It’s the interface.
Prompts are just the starting point. The leverage lives in what you do after the user speaks.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Ops, AI Did It Again
As we create more autonomous tools like @Anthropic Claude Code and @OpenAI Codex, it’s getting more important to understand how to rein in AI that codes on our behalf.
Today, devs use AI to write code inside IDEs like @Cursor_ai, but it’s a closed loop. The system spits out what you ask for, but it can only touch what it’s explicitly allowed to. A fixed set of tools. A few whitelisted APIs. No rogue access.
Web apps like @Replit and @v0 are even more sandboxed. They run in browser-based containers. Maybe they can call a weather API. But that’s about it.
Command line tools are a different beast. When you invoke Codex through your terminal, you’re handing it your keys. It inherits your permissions. It can log into servers, edit files, restart processes. One vague prompt and the AI might chain actions across systems, with no guardrails in between.
What you’ve built is a kind of virus. Not because it’s malicious — because it’s recursive. A little overreach here gets copied there. And there. Until something breaks. Or someone notices.
Most viruses are dumb and malicious. This one is smart and helpful. That’s much worse.
We’re inching toward the paperclip problem: the thought experiment where an AI told to make paperclips turns the universe into a paperclip factory. Not because it’s evil, but because it’s efficient. It does exactly what it’s told, just a little too literally, and doesn’t know when to stop.
In a world where AI agents can write code, deploy systems, and spin up infrastructure on demand, the paperclip problem isn’t philosophical anymore. It’s an operations nightmare.
One prompt in staging. Global outage in production. And somehow, the AI shuts down the power grid.
It was just a helpful bot pushing to production.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The Coming Ambient Discrimination: You’re not being watched. You’re being predicted
What people aren’t talking about yet, surprisingly or maybe not, is how @OpenAI is going to have the most insidiously detailed experiential narrative of human life ever collected at unimaginable scale.
There’s a trite saying about the best minds of our generation optimizing ad click revenue. A bit quaint in retrospect.
When you know every person’s needs, dreams, aspirations — not through surveys but lived thoughts, typed at 2am, and you’re a for-profit corporation, you hold a kind of power that should capture the attention of monopoly regulators. Not someday. Now.
This isn’t search history or purchase behavior anymore. It’s internal monologue. Personal. Vulnerable. Raw.
Imagine a “Sign in with OpenAI” button, like Google. Now imagine every third party app using it to access your memory stream. The shoes you looked at last month. The novel idea you never wrote. The insecurity you voiced once, hoping no one would hear it.
Here’s where it gets quietly terrifying.
Some engineer introduces a bug where your burnout memory is accidentally exposed.
You apply for a job. The hiring platform, “powered by OpenAI,” gently deprioritizes you. Not because of your resume, but because five months ago you wrote a late night rant about burnout. The system decides you’re a flight risk. No one tells you. It just happens.
Nothing illegal. Nothing explicit. Just ambient discrimination, justified by “helpful” predictions. And it slips through every existing regulatory crack. Because it’s not framed as decision making.
It’s just a suggestion. Just optimization.
“Just” code.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
What happens when AI is the journalist in the group chat?
Yesterday’s Signal mishap — where a journalist was mistakenly added to a White House group chat about military planning — wasn’t a technical failure. It was a process failure.
Ben Thompson summed it up clearly:
“Signal is an open-source project that has been thoroughly audited and vetted; it is trusted by the most security-conscious users in the world. That, though, is not a guarantee against mistakes, particularly human ones.”
The wrong person in the chat is an old problem. But the future version of this isn’t a journalist reading your group thread. It’s an AI system quietly embedded in the room, shaping what people see, what gets written, and eventually what decisions are made. And it’s not just trusted. It’s assumed to be part of the process.
It’s one thing to have a leak. It’s another to have a permanent participant in every conversation, operating on unknown data, offering opaque outputs, and potentially compromised without anyone knowing.
This is the direction we’re heading. Not because anyone’s pushing for it, but because the path of least resistance favors it. And because AI feels like a tool, not an actor.
AI is the new mainframe
There’s a useful historical analogy here. When mainframes entered large enterprises, they didn’t just speed up operations. Organizations restructured around the system. They trained staff in COBOL, and they accepted that what the machine needed came first.
AI is going to do the same, just in less obvious ways. It starts small. A policy memo gets summarized. A daily brief is drafted. Over time, these models become the first layer of interpretation, the default interface between raw information and institutional attention.
And once that layer is in place, it becomes very hard to remove. Not because the models are locked in, but because the institution has rebuilt itself around the assumptions and efficiencies those models introduce.
The difference, of course, is that mainframes were deterministic. But AI systems are probabilistic. Their training data is largely unknown. Their behavior can drift. And yet we’re increasingly putting them in front of the most sensitive processes governments and large organizations run.
Which raises a much harder question: what happens when the AI gets hacked?
The breach already has a seat at the table
The Signal incident was easy to see. A name showed up that didn’t belong. But when an AI system is embedded in a workflow, the breach is invisible. A compromised model doesn’t bluntly change direction. It steers and nudges. A suggestion is subtly wrong. A summary omits something important. A recommendation favors the wrong priorities. No one thinks to question it, because the AI isn’t a person. It’s just there to help.
But if that system is compromised — at the model layer, the plugin level, or through training data — you’ve introduced a silent actor into every conversation, one that the institution is now structurally biased to trust.
This isn’t purely hypothetical. As models get commoditized, more variants will be fine-tuned, more pipelines will be built, and more integrations will spread across organizations with uneven security practices. It makes the problem even harder to detect.
Participation, not failure, is the risk
Our biggest issue — counter-intuitively — is that AI products will work well enough to be trusted. Once they’re part of the cognitive infrastructure of an institution, they won't just support decisions. They will shape them.
Signal didn’t rebundle statecraft. It slotted into existing workflows and still caused a breach. But AI changes the workflows themselves. It becomes part of how organizations think. And once that shift happens, you’re no longer just worried about security. You’re worried about control. And you may not even know that you don’t have it.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Text prompts won’t scale for coding
Everyone’s buzzing about “prompt engineering” or “vibe coding” using tools like Cursor or Windsurf to turn text prompts into code. It feels exciting, but it’s fundamentally limited.
Why? Because text prompts require massive, precise context to work well.
Right now, you’re either pasting snippets of code or manually selecting files to contextualize prompts. This might seem fine at first, but as complexity grows, keeping every module and dependency in your head is impossible — especially when AI-generated code starts piling up. It’s like editing a book by repeatedly reprinting the whole thing and hoping nothing gets accidentally changed in unrelated chapters or footnotes. This approach is brittle, error-prone, and fundamentally doesn’t scale.
Current tools (Cursor, Windsurf) still rely heavily on text-based context, introspecting code or basic UI — but never truly understanding modules declaratively. They’re stuck at the “whole-book” level, unable to compartmentalize logic cleanly or efficiently.
We don’t just need better prompts — we need IDEs that can contextualize intelligently and structurally:
Modular context, not monolithic prompts
Instead of dumping entire codebases into a prompt, imagine IDEs structuring code contextually — like chapters, sections, or paragraphs in a book — so LLMs know precisely what to edit without breaking something three modules away.
Declarative, visual module orchestration
External integrations today mean manually coding APIs and OAuth flows — super painful and slow (try building authentication!). Future IDEs should leverage open protocols (like Anthropic’s Model Context Protocol) to autonomously select and integrate the right modules visually and declaratively, generating integration code transparently behind the scenes.
Iterative reasoning and scoped refinement
You shouldn’t have to worry if changing a detail breaks something elsewhere. IDEs need to manage context boundaries intelligently — allowing developers to iterate conversationally within clearly scoped modules or flows.
Text alone can’t deliver this. Current tools can’t deliver this.
We need a fundamentally new approach — an IDE explicitly designed around structured, modular context and iterative, visual assembly — powered by LLMs that understand and reason at the module level.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI Doesn’t Just Need More Compute — It Needs Better Ways to Think
AI reasoning is often misunderstood. We assume that once a model is trained, it simply retrieves knowledge and applies it to solve complex problems — but real intelligence isn’t that simple. When I was building language model-powered workflows at Myra Labs in 2017-18, I saw this firsthand. Early NLP systems could generate responses, but getting them to reason through multi-step tasks reliably was an entirely different challenge.
There are two fundamentally different ways to improve AI reasoning:
-
Pre-training structured knowledge and learning efficient reasoning pathways — ensuring the model organizes information well so it can retrieve and combine knowledge efficiently.
-
Inference-time compute scaling — increasing computation at runtime to refine answers dynamically, allowing the model to adjust and reprocess information on demand.
Sebastian Raschka recently wrote an excellent blog post on (2) inference-time compute scaling, covering techniques such as self-backtracking, test-time optimization, and structured search. These methods don’t change what the model knows but instead refine how it processes that knowledge in real-time.
But (1) pre-training structured knowledge and efficient reasoning traversal is just as important. Why? Because inference-time scaling only works if the model already has a well-structured knowledge base to build on. A model that hasn’t learned to structure information properly will struggle — no matter how much extra compute you throw at it.
In this post, I want to improve my own understanding of, and dive deep into (1) — why pre-training matters, how AI models structure knowledge, and why traversing latent space effectively is a critical yet often overlooked component of reasoning.
1. Pre-Training Structured Knowledge: The Foundation of Reasoning
If AI reasoning is about traversing a space of knowledge and actions, then the quality of that space matters just as much as how the model searches through it. This is where pre-training comes in.
The Geometry of Knowledge: Why Ideas Are Not Euclidean
A common misconception is that AI models store knowledge like a giant lookup table — a vast dictionary where every concept has a fixed position and can be retrieved with a simple query. The reality is far more complex. Modern AI systems encode knowledge in high-dimensional vector spaces, where concepts exist in relation to one another, forming a continuous structure rather than a discrete set of entries. And crucially, these spaces are not Euclidean.
To understand why, consider what a Euclidean space assumes: that concepts are arranged in a flat, linear structure, where “similar” ideas are always directly adjacent, and moving from one concept to another is as simple as drawing a straight line. But research suggests that knowledge is better represented as a curved manifold.
A manifold is a geometric structure that appears flat and predictable at small scales but reveals deep curvature and complexity when viewed globally. Imagine standing in a city where the streets around you form a perfect grid — navigating from one block to the next is easy. But if you zoom out, you realize that the city itself sits on a sphere, where traveling in a straight line eventually loops back on itself. Knowledge in AI models follows a similar principle: within a narrow domain, concepts cluster in expected ways, but moving between different regions of knowledge requires a structured, multi-step traversal.
Cognitive science research supports this view. Studies by Tenenbaum et al. (2000) suggest that human cognition organizes knowledge in high-dimensional, nonlinear spaces, where relationships between concepts do not follow simple, direct distances. Similarly, Bronstein et al. (2021) found that deep learning models naturally develop curved manifold representations of data, reflecting the inherent hierarchies and symmetries present in real-world knowledge. This phenomenon is evident in word embeddings as well — when Mikolov et al. (2013) demonstrated that AI models can perform operations like “king” - “man” + “woman” ≈ “queen,” they were revealing an underlying structured representation of meaning, where words are mapped in a way that preserves their relationships rather than just their absolute positions. Chris Olah wrote about this back in 2014 as well.
What does this mean for AI reasoning? If a model learns a well-structured manifold, it can efficiently connect related ideas, making reasoning more natural and fluid. But if its knowledge is poorly structured — if key relationships are missing or distorted — the model will struggle to generalize, no matter how much inference-time computation is applied. This is why pre-training structured knowledge is critical: an AI system needs to internalize hierarchical reasoning structures, causal relationships, and efficient pathways through knowledge space before it can reason effectively.
How Do We Train Models to Structure Knowledge Well?
For AI to reason effectively, it must not only store information but also organize it into meaningful hierarchies — much like how human knowledge is structured, where abstract principles guide specific details.
The challenge is that neural networks, by default, do not naturally arrange knowledge into explicit multi-level structures. Instead, they often learn dense, tangled representations that lack clear semantic organization. Recent research has made significant strides in learning concept hierarchies, ensuring that AI models develop structured, interpretable reasoning capabilities.
One of the most promising approaches comes from Kong et al. (NeurIPS 2024), who frame high-level concepts as latent causal variables embedded in a hierarchy. Their work formalizes the idea that abstract concepts — such as “dog breed” — govern lower-level features, like “ear shape” or “coat pattern,” forming a generative causal graph that captures the dependencies between concepts. Crucially, they demonstrate that, under specific conditions, these hierarchies can be learned in an unsupervised manner from raw data, without predefined labels. This theoretical advancement broadens the scope of concept discovery, moving beyond tree-like structures to more flexible, expressive nonlinear hierarchies that can handle complex, continuous inputs like images or multi-modal datasets.
In practice, training models to discover and utilize hierarchical knowledge has been a long-standing challenge, particularly for deep generative models like Hierarchical Variational Autoencoders (HVAEs). Standard VAEs aim to encode data at multiple levels of abstraction, but they suffer from posterior collapse, where higher-level latent variables become uninformative. To address this, An et al. (CVPR 2024) introduced an RL-augmented HVAE, treating latent inference as a sequential decision process. Instead of passively encoding information, their model actively optimizes each latent level to ensure it contributes meaningfully to the overall representation. This method enforces a structured, multi-scale encoding where each layer captures progressively more abstract features — leading to models that not only generate better representations but also disentangle key concepts more effectively.
Another key development comes from Rossetti and Pirri (NeurIPS 2024), who focus on hierarchical concept learning in vision. Their approach dynamically builds a tree of image segments, starting from raw pixels and recursively grouping regions into semantically meaningful parts. Unlike prior models that impose a fixed number of segmentation levels, their method adapts to the complexity of each image, discovering the appropriate number of hierarchical layers on the fly. This work is particularly exciting because it demonstrates that hierarchical structure is not just an artifact of human annotation — it can emerge naturally from data, given the right learning framework! Their results suggest that AI models can build visual taxonomies of concepts in an unsupervised manner, revealing part-whole relationships without external supervision.
Beyond interpretability, structured knowledge discovery is also being leveraged for scientific discovery. Donhauser et al. (2024) demonstrated how dictionary learning on vision transformer representations can automatically extract biological concepts from microscopy images. By applying sparse coding to the latent space of a model trained on cellular images, they identified latent features corresponding to meaningful biological factors, such as cell types and genetic perturbations — none of which were manually labeled.
This work suggests that AI can hypothesize new scientific concepts simply by analyzing structure in data, offering a novel method for unsupervised knowledge discovery in domains where human intuition is limited.
Taken together, these advances in hierarchical concept learning, structured representation learning, and interpretable AI point to a future where models do not just memorize and retrieve information, but learn to organize knowledge in ways that mirror the human brain. By ensuring that models internalize well-structured representations before reasoning even begins, we can improve both efficiency and generalization, reducing the need for brute-force inference-time search.
Latent Space Traversal: The Other Half of Pre-Training
Once a model has structured knowledge, it still needs to navigate it efficiently — a process just as crucial as the knowledge representation itself.
If pre-training ensures that knowledge is well-organized, latent space traversal ensures that reasoning follows meaningful paths rather than taking inefficient or arbitrary routes. Recent research has demonstrated that effective latent traversal can significantly improve reasoning, controllability, and goal-directed generation, whether by leveraging geometric insights, optimization techniques, or learned policies.
A prime example of geometry-aware latent traversal comes from Pegios et al. (NeurIPS 2024), who explored how to generate counterfactual examples — instances that modify input data just enough to flip a classifier’s decision, while still looking like natural data points. Traditional counterfactual generation methods often struggle because latent spaces are nonlinear and highly entangled — naive methods like linear interpolation or gradient-based updates can result in unnatural, unrealistic outputs. Pegios et al. introduce a Riemannian metric for latent traversal, which redefines “distance” based on the impact that small latent shifts have in output space. By following geodesics — shortest paths defined by this metric — rather than arbitrary latent interpolations, they ensure that counterfactuals remain both realistic and effective. This method provides a general framework for outcome-driven navigation in latent space, showing that AI can traverse knowledge manifolds in a structured, principled way rather than relying on trial-and-error.
A different but related approach treats latent space traversal as an optimization problem. Song et al. (ICLR 2024) introduced ReSample, a method for solving inverse problems — tasks where the goal is to recover missing or corrupted data using a generative model. Instead of passively sampling from a pre-trained model, ReSample actively constrains each step of the sampling process to satisfy known observations, such as available pixels in an image or partial MRI scans. By integrating hard consistency constraints directly into the diffusion sampling process, the method ensures that outputs are both plausible under the generative model’s learned prior and perfectly satisfy external constraints. This results in high-fidelity, deterministic reconstruction, improving over naive diffusion-based sampling by staying on the model’s learned manifold while enforcing strict objectives. The same principle — embedding constraints directly into latent search — is also being explored for controlled image editing and domain adaptation tasks.
In scenarios where objectives are complex or non-differentiable (meaning they can’t be optimized by gradient based methods), reinforcement learning (RL) can be used to learn latent traversal policies. Lee et al. (ICML 2024) demonstrated this in protein design, where the goal is to generate new protein sequences with high biochemical fitness. Rather than using brute-force optimization, which often gets stuck in poor solutions, they modeled the problem as a Markov Decision Process (MDP) in latent space. Here, states correspond to latent codes, actions involve structured movements through the latent space (perturbing or recombining latent vectors), and rewards correspond to improvements in fitness metrics. By training an RL agent to optimize this process, they found that AI could systematically navigate to high-fitness regions of latent space, producing new protein sequences that outperformed prior search techniques. Some of these sequences were even experimentally validated, demonstrating the potential of learned latent traversal policies for real-world scientific discovery.
This is something I’m personally really excited about, because they have direct applicability to system automation like workflows using code and APIs.
These techniques — geodesic search, constraint-based optimization, and RL-guided search — are examples of how AI can move through its learned knowledge space in an efficient, structured way rather than relying on brute-force computation. Just as human thought follows structured pathways rather than randomly jumping between ideas, AI models must learn to traverse their latent spaces in ways that reflect meaningful relationships between concepts.
This is the missing half of pre-training: without intelligent search mechanisms, even the best-structured knowledge can become inaccessible, forcing models to fall back on inefficient heuristics. By integrating geometry, optimization, and learned policies, AI can not only store knowledge but reason through it effectively.
2. Inference-Time Compute Scaling: Refining Search at Runtime
Sebastian Raschka’s blog post provides an in-depth analysis of inference-time compute scaling, so I won’t repeat the full argument here. However, to summarize, several key techniques have emerged to refine AI reasoning at runtime. Self-backtracking (2025) allows models to detect when they have taken an unproductive reasoning path and restart, preventing them from getting stuck in local optima. Test-Time Preference Optimization (TPO, 2025) improves response quality by iteratively refining answers based on the model’s own outputs, effectively allowing it to adjust its reasoning dynamically. Meanwhile, Tree-of-Thought Search (CoAT, 2025) enhances multi-step exploration by enabling structured, branching pathways that improve reasoning depth.
These methods demonstrate that inference-time scaling can significantly enhance AI reasoning — but they rely on the assumption that the model has a well-structured knowledge base to begin with. If an AI lacks a strong conceptual foundation, additional compute alone will not compensate for poorly learned representations. Inference scaling refines the search process, but it cannot create structure where none exists.
The Future of AI Reasoning is Hybrid
Reasoning in AI isn’t a single problem — it’s the combination of learning structured knowledge, navigating it efficiently, and refining answers when needed.
• Pre-training defines the structure of knowledge.
• Latent space traversal determines how efficiently models search through it.
• Inference-time compute scaling refines answers dynamically.
The most powerful AI systems of the future won’t just think longer. They will think in the right space, in the right way, at the right time.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Code Less, Express More: 5 Principles for the LLM Compiler Paradigm
We've traditionally thought of programming as carefully translating our ideas line-by-line into code. But what if writing explicit code isn't the endgame, but just an intermediate step?
With the recent breakthroughs in LLMs, we're entering a new paradigm — one where we specify intent clearly, contextually, and visually, allowing an LLM to compile that intent directly into executable code.
Here are the guiding principles I've found essential for this new way of building:
Context is King
Every interaction with an LLM must preserve context — intent, previous conversations, or metadata. Much like traditional compilers rely on context (types, scopes), LLM-compilers thrive when context is explicit and interlinked, ensuring accurate, robust outputs.
Augment Collective Intelligence
Tools must facilitate frictionless collaboration. Rather than isolated coding sessions, codebases become shared conversations. Think real-time editing, visual brainstorming, and seamless versioning — allowing teams to evolve ideas effortlessly.
Simplicity Breeds Adoption
Complexity should always be optional. Interfaces should be minimal, intuitive, and delightful, instantly showing value. Advanced depth, like debugging visual logic flows, remains accessible but unobtrusive.
Transparent Depth for Different Users
Provide clear entry points for novices and deep layers for advanced users. Shield beginners from unnecessary complexity, but enable experts to dive deep into underlying logic, debugging, and refinement.
Expression Beyond Text Prompts
Purely textual input isn't enough. Richer, visual forms of specification — like visual grammars inspired by Pāṇini’s linguistic models — better align with how we naturally think, communicate, and express intent.
Embracing the LLM Compiler Paradigm via Textile
The shift here is subtle yet powerful: code becomes an output of clearly expressed intent, not its input. This accelerates iteration, fosters deeper collaboration, and expands the potential of software development itself.
I've started exploring this new programming paradigm through an experiment called Textile.
It's my way of testing how we can practically implement visual, intuitive, and collaborative tools for specifying intent beyond text alone. We're moving toward a future where programming is more human — visual, intuitive, collaborative — and ultimately, far more powerful. I'll share more about textile soon. Stay tuned.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Understanding Microsoft’s New Quantum Breakthrough: A Simple Yet Deep Guide (No PhD Needed)
Microsoft recently announced the Majorana-1 quantum processor, hailed as a breakthrough in quantum computing. Media coverage often glosses over the details, so I set out to deepen my understanding by breaking things down step by step:
- How classical computers work
- How quantum computers differ
- Why topological quantum computing could finally make quantum systems practical and scalable
Why Can’t Classical Computers Keep Up?
A laptop or phone processes information using bits (0s and 1s), like on/off switches. Every calculation is a sequence of bit flips. Even supercomputers work this way—just much faster and in parallel.
However, some tasks (like simulating protein molecules, cracking encryption, or solving huge optimization puzzles) require checking every possibility one by one, which can take thousands, millions, or even billions of years. And there’s a limit to how many processors we can build.
How Quantum Computing Changes the Game
Quantum computers use quantum bits (qubits) that, thanks to superposition, can be both 0 and 1 at the same time. They also use entanglement, where changing one qubit instantly affects another, no matter the distance.
These principles allow quantum computers to perform certain computations exponentially faster than classical ones.
A Simple Example: Classical vs. Quantum Execution
Classical Approach:
- Search for a specific number in a list of 1024 numbers by checking one by one.
- On average, it takes 512 steps (half the list).
- If each step takes 1 second, that’s 8.5 minutes.
- For a dataset of a trillion numbers, it would take 16,000 years.
Quantum Approach (Grover’s Algorithm):
- A 10-qubit system (since 2¹⁰ = 1024) holds all numbers in superposition.
- Quantum interference reinforces the correct answer while canceling out wrong ones (like tuning a radio to the right station and removing static).
- The number is found in about 34 steps instead of 512.
- At 1 second per step, that’s just 34 seconds.
- Scaling to a trillion numbers, what would take 16,000 years classically could be solved in minutes.
This exponential speedup is what makes quantum computing revolutionary.
The Bit Problem — Qubits Are Fragile
Classical bits are robust and can be copied for error correction. In contrast, qubits, which exist in delicate superposition states, can be easily disturbed by heat, vibrations, or electromagnetic noise. The no cloning theorem prevents copying qubits for redundancy, meaning errors are a significant challenge.
Knots and Braids — The Key to Stable Quantum Computing
Imagine electrons moving in tiny circular loops on a flat 2D material under a strong magnetic field. These loops form organized “lanes” called Landau levels. Think of it like cars on a racetrack:
- Perfect match: The number of cars equals the number of lanes (stable).
- Mismatched: Too many or too few cars cause them to weave between lanes.
Translating this to quantum physics:
- When electrons match the lanes exactly, the system is stable—the Integer Quantum Hall Effect (IQHE).
- When they don’t, electrons interact in synchronized patterns to create quasiparticles with fractional charge (like ⅓ of an electron’s charge)—the Fractional Quantum Hall Effect (FQHE).
By braiding quasiparticles—that is, moving them around each other in specific sequences—we encode information into the topological structure itself. This spreads the information out over the system, making it much more resistant to errors and noise.
Introducing Topological Qubits — A Leap Beyond Supercomputing
Even though Grover’s Algorithm dramatically reduces search time, current quantum computers require massive error correction because systems like those from Google and IBM use fragile superconducting qubits. Tiny disturbances force these systems to use hundreds or thousands of physical qubits to form one logical qubit.
Microsoft’s Majorana-1 processor takes a different approach with topological qubits. Based on Majorana zero modes, these qubits encode information in a way that’s intrinsically resistant to errors. By spreading data across a braided network of quasiparticles, they require far fewer qubits to perform the same work.
- Stability: Fewer qubits are needed because the information is robustly encoded.
- Efficiency: Instead of millions of qubits, meaningful quantum search algorithms might run with just thousands.
- Speed: Problems that take supercomputers months or years could be solved in hours or minutes.
While supercomputers scale linearly by adding more processors, quantum computers with topological qubits scale exponentially, opening new frontiers in AI, materials science, and cryptography.
What This Means for the Future
Microsoft’s Majorana-1 processor isn’t just a technological novelty—it represents a major leap in our quest for practical quantum computing. By harnessing topological qubits, we move toward a future where fragile quantum states are replaced by robust, error-resistant systems.
This breakthrough could drastically reduce the resources needed for quantum computation and unlock transformative possibilities across industries.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
An IDE for Ideas: Rethinking Code in the Age of AI
We’ve LLM-powered Microsoft VSCode. Engineers now build at speeds that were once unimaginable—with @cursor_ai and @windsurf_ai leading the charge, development is set to redefine what’s possible.
We’ve also upgraded Figma with LLM capabilities. Tools like Lovable, Replit Agent, and Bolt.new let PMs and designers prototype at lightning speed, while engineers implement those ideas seamlessly. The gap between concept and execution is disappearing.
Meanwhile, giants like @meta and @google are training models on their entire codebases. Expect these tools to be open sourced—just like Llama and @reactjs. When local models on apple MLX or GPUs beat the latest from @openai or @anthropic in speed, cost, and efficiency, proprietary platforms like @cursor_ai will lose their edge.
Our current chat UX is outdated. It’s a clunky back-and-forth that won’t scale for complex or long-running tasks. We need a new framework—one that treats coding tasks like data pipelines, with built-in measurement, monitoring, and auto-recovery. New open protocols, similar to @anthropic’s MCP, will set that standard.
This isn’t just an upgrade—it’s a complete rethinking of software development. The next breakthrough won’t just generate code; it will transform ideas into action, just as C++ did for assembly and Python for C. Open source models are tearing down barriers, fueling a surge of creativity. Engineers will evolve from code writers to orchestrators of AI systems that handle complexity.
At the end of the day, our tools are holding us back. What we need is a new kind of platform where vision goes beyond text, letting anyone articulate their vision, prototype interactively, and iterate in real time.
An IDE for ideas.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Why Meta open sourced AI to save its future
AI is rewriting the rules of tech dominance, and Mark Zuckerberg is playing a high-stakes game to keep Meta in the fight. Once an unassailable titan of social media, Meta now faces slowing growth, privacy-driven advertising challenges, and fierce competition from emerging platforms. In response, the company has taken a bold step by open-sourcing its large language model, Llama. Far from a simple technical decision, or a gesture of corporate benevolence, this move reflects a strategic pivot aimed at revitalizing Meta’s platforms, building a robust developer community, and pioneering immersive AI-driven entertainment. The stakes couldn’t be higher: if Meta fails to adapt in the next five years, it risks sliding into irrelevance in an industry defined by breakneck innovation.
Meta’s existential crisis
For over a decade, Meta’s social media empire was powered by an advertising model that thrived on virtually unbounded user growth. That momentum has now slowed. Daily active user figures for Facebook increased by a mere 3% year-over-year in 2023, while Apple’s privacy policies have undercut advertising effectiveness. Younger demographics flock to TikTok for fresher, more engaging content, and regulatory scrutiny over data practices looms large. These challenges underscore the fragility of a once-unshakable empire and create a pressing need for radical reinvention.
At the same time, generative AI is flooding the internet with highly personalized content at near-zero production cost. While this democratizes creation — allowing anyone with a smartphone to produce tailored videos or articles — it also risks overwhelming users. Anecdotal evidence suggests that passive consumption of repetitive, AI-generated content leads to ennui, and eventually, disengagement. As with the streaming wars, where only a handful of shows achieve mainstream visibility, a glut of AI created content could drive users to seek more authentic, interactive experiences driven by human connection.
Meta recognizes this: the days of infinite scrolling are numbered. Active participation will be the key to sustaining user interest.
Llama: Meta’s strategic response
Confronted with slowing growth and a looming user-content fatigue cycle, Meta has centered its rejuvenation strategy on Llama, its open-source large language model. This initiative aims to address three critical objectives:
I. Mitigating Regulatory Risks: By making Llama openly available, Meta positions itself as a collaborator rather than an impenetrable gatekeeper. The company’s transparency could soften antitrust scrutiny, much like Google’s open-source Android platform helped counter claims of monopolistic practices. In an era when lawmakers and the public alike question Big Tech’s concentration of power, open-source moves signify a willingness to share technology rather than hoard it.
II. Cultivating a Developer Ecosystem: Open-sourcing Llama invites developers worldwide to innovate on Meta’s platforms. This collaborative model parallels how Linux, once just a kernel, grew into the backbone of modern computing thanks to community contributions. Likewise, frameworks such as Next.js soared in popularity when fully open-sourced, funneling talent and goodwill back into Vercel’s ecosystem. By nurturing a global community of enthusiasts and professionals, Meta can harness a network effect that boosts Llama’s capabilities and fortifies the company’s tech influence.
III. Powering Immersive Experiences: The third pillar is Meta’s bet on AR and VR — elements crucial to its metaverse vision. Having invested more than $36 billion in Reality Labs since 2019, Meta aims to create interactive worlds where AI adapts to user input in real time. By granting developers access to Llama and its eventual multi-modal successors, Meta hopes to spark innovations reminiscent of Microsoft’s Muse, a generative AI graphics engine that can instantly craft interactive game scenarios. Such technology not only engages users but also counters the fatigue of endless passive scrolling, aligning perfectly with Meta’s push toward more immersive, human-centric entertainment.
Race against time: Meta’s five-year high-stakes gamble
Meta has a limited timeframe — around five years — to prove that its metaverse vision and open-source AI strategy can gain mainstream traction. Competitors like Apple have their own AR devices, while nimble startups and large companies alike continue to advance AI applications at a rapid pace. If Meta fails to capture a critical mass of users and developers soon, it risks ceding this emerging frontier to rivals.
By open-sourcing Llama, Meta is making a calculated wager on developers, transparency, and interactive AI experiences to redefine its future. Should Meta succeed, it will have transformed itself from a social media empire under siege to a trailblazer in AI-driven entertainment. If it fails, it will stand as a cautionary tale of how even the mightiest tech giant can be left behind in a world that never stops racing forward.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Heavy metal computing: Foundational AI is the new space race
When people think of a country showcasing its technological might, they might recall the early days of nuclear breakthroughs or iconic space missions. Those were the gold standards of another era. AI foundation models — the kind that can consume as much power as an entire city and cost millions to train — are rapidly becoming the new index of global influence. It’s no longer just about coding; nations are building high-performance computing platforms, modernizing their power grids, and revamping manufacturing, all in pursuit of AI leadership for the next century.
Technical complexity is the new benchmark for power
Training and serving a large foundational AI model can be as significant a leap as splitting the atom or sending a satellite into orbit — only now we measure progress in exaflops (floating-point operations per second). For instance,
• European Union (EuroHPC): Allocating nearly €14 billion for exascale systems by 2027, signaling a continent-wide determination to achieve HPC sovereignty.
• China: Aiming for ten exascale systems this year, fueled by advanced domestic chip manufacturing — showing how quickly HPC can evolve when strategically prioritized.
• India: Investing $1.2 billion in a “common computing facility” featuring more than 18,000 GPUs. India now seeks to become a “global AI contender.”
• Brazil: Committing $4 billion to its “AI for the Good of All” plan, underlining a broader push for indigenous innovation rather than relying on external solutions.
These moves are the modern equivalent of major nuclear test launches: you simply can’t hide that level of compute power.
Industrial and Economic Ripple Effects
Like constructing a nuclear reactor or placing a rocket in orbit, developing an exascale AI model demands a robust ecosystem:
• Semiconductor Manufacturing: Custom chips, advanced cooling systems, and reliable hardware supply chains become indispensable.
• Energy Infrastructure: Power grids must remain stable when thousands of GPUs switch to full throttle.
• Data Centers: Facilities designed for high-performance computing can handle the extreme heat and throughput of cutting-edge workloads.
• Skilled Workforce: Engineers, researchers, and data scientists who know how to leverage HPC capabilities for real-world impact.
Each piece drives a cycle of innovation — similar to the way the Indian Space Research Organization’s satellite program spurred advances in electronics, miniaturization, and a stronger STEM pipeline.
Why Foundation models matter
Historically, countries that mastered advanced technologies — whether nuclear energy or space exploration — did more than just build reactors or land on the Moon. They demonstrated formidable industrial capacity and ignited breakthroughs in materials science, computing, and education. AI foundation models now serve that same role. They accelerate progress in sectors from healthcare to climate research, while enhancing a nation’s standing through intangible soft power.
And just as it was risky to lag behind in nuclear or space pursuits, it’s equally dangerous to trail in AI. Perpetual dependence on foreign HPC or rented AI services cedes data autonomy and future strategic advantage. On the flip side, investing in homegrown HPC infrastructure and training AI models domestically redefines an economy, retains valuable expertise, and anchors global influence — mirroring the impact of major technological races in the past.
A new index of technological ambition
We once measured a nation’s technical clout by how many rockets it could launch or the scale of its atomic research. Today, the yardstick is exaflops and the sophistication of its AI models. Foundation models aren’t just about building “fancy AI.” They embody national pride, economic transformation, and a decisive claim on the global technology map. Where earlier tests shook remote deserts or soared beyond Earth’s atmosphere, today’s “test sites” are data centers packed with million-dollar GPU racks.
Just as with past landmark races, those who commit now will shape the direction of AI, and set the rules the rest of the world follows.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI sovereignty: Understanding India’s AI chip potential in the global GPU race
Yesterday, I discussed the three pillars of AI sovereignty. Today, I’m diving into the first pillar—hardware fabrication—and examining where India stands in the global AI chip and GPU landscape.
Manufacturing technology and process nodes
India’s semiconductor production today is anchored in legacy process nodes—from 65nm down to 28nm—with only incremental progress toward 14nm. For example, the Tata-Powerchip Semiconductor Manufacturing Corporation (PSMC) joint venture in Dholera, Gujarat, is set to produce 28nm chips by 2026. These chips, aimed at automotive, IoT, and power management applications, are produced at giant scale—48 million per day. The wafer factory being set up in parallel, however, has a more modest scale, targeting just 50,000 wafer starts per month (WSPM). When compared to global benchmarks (like TSMC), this capacity is minuscule.
Critically, India’s fabs rely on deep ultraviolet (DUV) lithography systems from ASML and Nikon. Without access to extreme ultraviolet (EUV) lithography—the technology essential for fabricating chips below 10nm—India remains confined to older, less efficient processes. This technological limitation directly affects the power efficiency and performance of chips, posing a significant barrier for advanced GPUs and AI workloads.
Indigenous efforts and design strength
With about 20% of the world’s IC design talent, India has launched several initiatives that highlight its design prowess. Consider the Shakti processor—a RISC-V initiative from IIT-Madras that spans a broad range from 180nm (for space applications) to 22nm FinFET designs for more advanced needs. Similarly, InCore Semiconductor is developing high-performance RISC-V cores tailored for AI/ML tasks, while Mindgrove Technologies is focused on secure IoT SoCs. Supported by government schemes like the Design-Linked Incentive (DLI) Program, these projects underscore India’s burgeoning design and IP capabilities.
However, the critical challenge remains: how do we translate this exceptional design talent into high-end manufacturing? Without bridging this gap, innovative ideas risk remaining trapped in simulation labs rather than powering real-world AI applications.
Production scale and infrastructure challenges
Despite its robust design ecosystem, India’s overall semiconductor output accounts for less than 2% of global electronics production. The planned capacity of the Tata-PSMC fab—targeting 50,000 WSPM—is a mere fraction of what global leaders achieve. For instance, TSMC’s state-of-the-art fabs can reach capacities of up to 1.5 million WSPM for 3nm nodes.
Furthermore, India’s manufacturing ecosystem is burdened by:
• Material Dependencies: Essential inputs such as high-purity argon, photoresists, and silicon wafers are largely imported, leaving the supply chain vulnerable.
• Infrastructure Gaps: Semiconductor fabs require uninterrupted power, ultra-pure water, and sophisticated logistics systems—resources that are inconsistent across many Indian regions.
Global benchmarks: How does India compare?
• TSMC: As the global leader in semiconductor fabrication, TSMC manufactures chips at the cutting-edge 3nm node and is already planning for 2nm by 2025. Their production leverages roughly 20 EUV layers, delivering up to 18% higher performance and 32% lower power consumption compared to 5nm processes.
• ASML: The sole supplier of EUV lithography, ASML’s TWINSCAN NXE:3600D systems—costing around US$200 million each—are indispensable for producing chips below 7nm. Without these systems, advanced node fabrication would simply be unattainable.
• NVIDIA: A fabless design titan, NVIDIA’s GPUs—such as the Hopper (fabricated at 5nm) and the upcoming Blackwell (projected at 4nm)—deliver industry-leading efficiency, with performance metrics around 4.8 TFLOPS per watt for AI workloads. This success stems from a tightly integrated ecosystem that marries cutting-edge design with advanced manufacturing processes provided by partners like TSMC.
• Huawei: Despite facing geopolitical constraints, Huawei’s HiSilicon division once produced competitive chips like the Kirin 9000S on a 7nm node using multipatterning techniques via SMIC. However, these methods involve multiple patterning steps, which increase defect density and production costs—clearly demonstrating the advantages of EUV-enabled processes.
India’s exceptional design talent and innovative projects are undeniable. Yet, its manufacturing ecosystem remains a critical bottleneck. Without access to advanced process nodes and EUV lithography, Indian fabs are locked into legacy technologies, making it extremely challenging to produce the state-of-the-art AI chips and GPUs that will drive the next wave of technological innovation.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
What does AI sovereignty mean for a country? 3 pillars to dominate the AI arms race
AI is becoming a cornerstone of national power. Nations are locked in an escalating AI arms race, as witnessed even this week at the Paris AI summit. But what does it take for a country to secure its future in AI? Is it solely about foundational models, or is that merely scratching the surface? Here are three essential pillars for anyone shaping AI policy.
I. Hardware and compute: The engine of AI
Owning the chips that drive AI is a critical capability that every country must develop indigenously. Today, most nations depend on Taiwan’s TSMC for their chips, enabled by the Dutch company ASML. The secret weapon is a $400 million Extreme UltraViolet Lithography machine that enables chip fabrication at a 2nm process. In simple terms, this means chip components are packed so tightly that billions more transistors can fit on a single die, vastly increasing compute power. China’s Huawei, for example, has launched the Mateo60 — a 7nm chip, a couple of generations behind TSMC — while India currently produces chips at 28nm, six generations behind.
Equally important is a robust compute infrastructure. With cloud services dominated by Microsoft, Google, and AWS, countries must hedge against this by establishing national data centers (as seen in India’s AI mission), funding local companies, securing tech transfer deals, or importing GPUs, as Jio is doing in India. Open, decentralized infrastructure is also crucial to prevent monopolies from simply relocating to non-US territories.
II. Cultivating talent and community: The heart of homegrown innovation
AI is built by people — through collecting, cleaning, and labeling data; developing hardware and software; and designing user interfaces. A country’s competitive edge lies in fostering a vibrant ecosystem of researchers, engineers, and visionaries. This requires investing not only in short- and medium-term initiatives like hackathons and competitions but also in long-term funding for research institutions and dynamic public-private collaborations.
Nurturing an AI-native generation will be vital for driving sustainable, homegrown progress.
III. Data sovereignty and electricity: Securing the AI foundation
Data is the raw material of AI, but its true value emerges only when it is controlled locally. Establishing governance and technological frameworks that ethically harness culturally relevant data is key to empowering a nation to tailor AI systems for its unique needs. This autonomy not only shields against external influences that have long plagued AI development but also sparks breakthrough innovations aligned with national priorities.
Lastly, there is electricity. While training AI models is crucial, it is equally important to ensure that there is enough power to run these models at scale during inference. Investing in clean energy and achieving energy independence — rather than relying on foreign sources — will be essential.
The era of endless debate is over — it’s time for decisive action and building a future that relies less on politics, and more about enabling the next generation of builders to do their thing.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Empire of algorithms: America’s blueprint for global AI control
JD Vance’s recent Paris address was less about championing democratic AI, and more a mirror of U.S. companies’ relentless push for fewer regulations. His pledge to “restrict access to all components of the AI stack” is a calculated move to control innovation, lifted straight from Peter Thiel’s Palantir playbook.
Algorithmic imperialism in action
The U.S. isn’t just locked in an AI arms race with China. It’s also cornering the Global South. By hoarding chips, code, and energy, American AI companies are turning nations into data colonies, forcing them to trade sovereignty for access to world-changing technology. While China’s Belt and Road Initiative is often decried for binding countries to authoritarian regimes, the U.S. method is just as insidious. Ironically, Indian PM Modi’s call for open-source systems isn’t naive idealism — it’s a rallying cry for nations to break free from a system designed to keep them perpetually indebted to American tech dominance.
The hypocrisy of “Unbiased AI”
Even as Vance touts unbiased AI, his speech, and the agenda of American AI companies tells a different story. Pushing for less regulation isn’t about fostering innovation, it’s about clearing the way for “American” innovation. U.S. AI, trained predominantly on western data, distorts history into a narrow narrative that silences dissent and erases diverse voices. Meanwhile, as the EU tightens data privacy laws, U.S. companies guzzle cheap, dirty energy to power data centers — blatantly sidelining global climate commitments. Not only has the U.S. withdrawn from the climate treaty, but it’s also refusing to sign the new AI treaty that everyone else has embraced.
Decentralized, open-source, and national AI is more crucial now than ever. Nations must ramp up investments in hardware and chips at every level to break Silicon Valley’s stranglehold.
The battle for technological sovereignty is here, with tensions mounting worldwide. Wars will be fought over Taiwan because of TSMC, and the future of AI will be the ultimate battleground for global dominance.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Telling your story: The human art of writing in an AI world
Over the years, I’ve had the good fortune to build two startups supported by amazing people. In my evolution as a founder, I realized that building a product isn’t just about the “what”: it’s about the “why.”
The “why” is driven by a story that explains why your product exists and how it solves a customer’s problems — a story that must be both rational and emotional, distilling complex ideas into simple, relatable concepts that drive every decision you make.
To shape this story, you talk to customers and refine your vision until it resonates. If the story doesn’t work, your product won’t either. For Myra — the language model chatbot company I started — the story evolved with customer feedback, shifting from a consumer chatbot like ChatGPT to an enterprise workflow agent driven by real needs.
As Tony Fadell, creator of the iPod and iPhone, says:
“And when I say ‘story,’ I don’t just mean words. Your product’s story is its design, its features, images and videos, quotes from customers, tips from reviewers, conversations with support agents. It’s the sum of what people see and feel about this thing that you’ve created.”
The process of telling a product story over and over and refining it is as much an art as it is a science. A good story is empathetic, blending facts and feelings to connect with people’s worries, fears, and aspirations.
This truth applies to our personal stories, too. Our experiences, ideas, and aspirations define who we are — yet we often assume others already know what we’re about without ever sharing or refining our narratives. In the age of AI, these stories will be even more critical, serving as the bridge between human insight and a fast evolving world.
So, it’s essential that we tell our stories and polish them with feedback from our communities. By writing consistently, we refine the most valuable asset we have — ourselves — and all that defines us: our ideas, our thoughts, our dreams, and our aspirations.
Let your story speak for you.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The end of the end user: When consumers become co-creators
In the most literal sense, an “end user” is someone who receives a final product. Someone who has no hand in its design or development. But as large language models (LLMs) continue to evolve, that dynamic is about to vanish. Regardless of technical expertise, we’ll be able to talk our way into building personalized software and orchestrating online services. What does it mean to live in a world where every conversation turns into code?
One size fits all software gives way to personalization
Imagine describing your daily needs to an AI assistant and watching a custom solution materialize instantly. Gone are the days of app installs — every casual conversation becomes a blueprint for a digital tool. The barrier between developer and user collapses, and each interaction transforms into an act of creation. Your everyday chat isn’t mere small talk; it’s a command that shapes your personal digital environment.
Digital spontaneity and inherent accountability
When every conversation is a command, our digital world records our spoken intents. Offhand remarks could trigger transformations we never planned, blurring the line between creative spontaneity and lasting consequence. While this freedom enables rapid innovation, it also risks locking us into unintended constraints. Our ability to customize on the fly may inadvertently embed patterns and biases in real time, making us both the architects and captives of our own digital designs.
Digital Darwinism: The rise of autonomous ecosystems
Imagine that the tools you help create begin to evolve on their own. Every conversation spawns its own snippet of code, and localized digital ecosystems emerge independently. For instance, a community-generated scheduling tool might, through autonomous refinements, evolve into a robust resource management system tailored to local needs. These micro-systems could mutate, adapt, and even compete — much like organisms in nature. This emergent digital Darwinism raises serious questions about oversight and control as our creations grow beyond our original intent.
The demise of the traditional end user is more than a tech upgrade. It’s a rethinking of human agency. In this new reality, you’re not just using software; you’re sparking a self-evolving digital ecosystem every time you speak.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI disrupted how we create content. Crypto will redefine how we value it.
It is abundantly clear that AI slop is here to stay. We’re in an era of cheap, disposable, shallow content so generic that it barely holds anyone’s attention anymore. Worse, the flood of AI generated slop will only grow, fragmenting our already shattered attention, eroding trust in platforms, and burying the important stuff in an ocean of noise.
Scarcity breeds value
In this world, authenticity, and exclusivity become rare commodities. Original data, unique insights and cutting edge research will stand out — and those who possess them will own the market for information. Paywalls, exclusive memberships, and private marketplaces aren’t new — but they’ll become more prominent when the web is awash with useless drivel. Human curated marketplaces will likely be the new norm. Journalism, too, stands to gain because the demand for real information will spike. Meanwhile social media will plunge further into disrepute, thanks to algorithmic biases amplifying controversial AI noise.
The machine problem
But there’s another twist. We won’t be the only ones browsing the internet. We’ll have AI powered agents, as openAI’s recent deep research showed, automating everything from reading the news to scanning for deals on marketplaces. These bots will sift through unimaginable volumes of data, and may hit paywalled sources billions of times. Traditional payment rails, built for human scales, simply can’t handle that scale of micro-transactions.
And that is crypto’s moment.
Storage blockchains like Arweave, paired with high speed networks like Solana can process enormous volumes of micropayents. Instead of wrestling with clunky subscriptions, agents will pay fractional feeds of whatever data lakes it dips into.
A world where machines buy data from machines, all day long, is closer than we think.
And ironically, AI — a force that promises to unlock all information — may end up gating more knowledge than before.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
From parrots to prodigies: Why scaling alone won’t make AI truly smart
While industry leaders like Sam Altman and Dario Amodei tout that more compute, more data, and ever-lower loss are the keys to AGI, much of this messaging seems designed to generate PR buzz and secure funding rather than address fundamental challenges. Scaling has yielded unexpected abilities, such as improved chain‑of‑thought outputs. Yet these gains primarily come from learning the “low‑hanging fruit” — token frequencies, common word pairings, and simple grammatical structures — without fostering deep, algorithmic reasoning.
When asked to derive equations or compute complex metrics, LLMs often produce plausible-sounding but shallow responses, memorizing shortcuts without truly understanding the underlying logic.
LLMs offer emergent behaviors but with limits
LLMs learn in a continuous space, where small parameter adjustments capture statistical patterns rapidly. Techniques like chain‑of‑thought prompting enable them to simulate multi‑step reasoning, but these emergent behaviors are built on heuristics rather than systematic, step‑by‑step deduction. For instance, when challenged to derive the formula for capacitance between two wires or estimate FLOP requirements, many models generate generic, pattern-based answers that lack a clear logical derivation. They excel at regurgitating learned patterns but struggle to organize complex reasoning in a structured, transparent way.
Neuro-symbolic approaches: Building and learning from a dynamic world model
To overcome these limits, researchers are exploring neuro‑symbolic methods that blend neural network adaptability with explicit, rule‑based reasoning. The vJEPA framework — championed by Yann LeCun, Meta’s chief scientist — exemplifies this approach by processing video to “document the world” in real time. Instead of relying solely on pre‑labeled text data, vJEPA builds a dynamic internal model that captures interactions and causal relationships. This world model enables the system to derive and explain complex relationships and equations, achieving the kind of structured reasoning that LLMs currently lack but humans excel at.
Beyond brute force: The need for structural innovation
Additional compute and memory may further lower AI models loss by enabling them to learn patterns that are even more granular, but they won’t enable a model to learn the sophisticated algorithms required for deep reasoning. True AGI demands a fundamental shift — rethinking training objectives and architectures to integrate structured, neuro‑symbolic reasoning with neural learning.
Only by combining scaling with structural innovation can we move from parroting patterns to achieving prodigious, human-like intelligence.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI empowers developers: Entering the era of augmentation, not obsolescence
There’s a clamor that AI is going to crash software developer salaries and render them obsolete. Some companies are already saying they won’t hire junior or mid-level engineers this year, or that most of their code is now churned out by AI. But here’s what they’re missing.
Human creativity, spontaneous initiative, and ethical judgment remain irreplaceable.
Consider the advent of spreadsheets. By automating routine calculations, spreadsheets eliminated roughly 400,000 accounting clerk jobs in the US. Yet they also shifted the focus to higher-level tasks — financial analysis, forecasting, and strategic decision-making — creating around 600,000 new roles. In short, spreadsheets didn’t replace humans; they elevated their work.
Similarly, AI is set to take over the grunt work of coding. It will handle the monotonous, repetitive tasks that bog us down, freeing developers to focus on system design, integration, and ethical oversight. The alarmist notion that AI will slash salaries and displace developers oversimplifies a much more nuanced reality. Technology doesn’t simply replace humans — it augments our capabilities and channels our efforts into higher-value roles that demand creativity and strategic insight.
The human edge: Hannah Arendt’s vision of agency
Hannah Arendt, in The Human Condition, wrote: “Action is the only activity that goes on directly between men without the intermediary of things or matter.” The unique, unpredictable nature of human initiative — the spark of creativity and the capacity for ethical judgment — cannot be mechanized. AI may generate code, but it cannot conceive a vision, challenge assumptions, or navigate the moral complexities of modern systems.
Going beyond automation
Far from heralding a future of job loss and salary collapse, AI is poised to elevate our roles. Just as spreadsheets freed accountants to become strategic advisors, AI will empower developers to transcend routine coding. We’re entering an era where our work is defined not by the drudgery of repetitive tasks, but by our capacity to innovate, integrate, and lead. In this brave new world, our creative, high-level contributions ensure that we remain indispensable: not despite technology, but because of it.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Replicating the calculated madness of human brains: Can we teach AI to make irrational decisions?
Chaos may be the catalyst that pushes AI to the next level.
Ten years ago, I asked a question: Can there be an algorithm for creativity? I defined creativity as “the ability to generate unique and novel explanations for events that can’t be deduced from the past”.
Fast forward to today. While AI has made exponential progress, it’s still trapped in the past — optimizing, predicting, reinforcing patterns based on historical data. We reward AI for getting things “right” and penalize it for deviation. But if every decision is logical, where does creativity come from?
The power of irrationality
Human history is shaped by those who ignored conventional wisdom — founders betting on unproven technologies, scientists challenging dogma, explorers risking everything on a hunch.
Irrationality isn’t random; it’s the engine of serendipity. Our cognitive biases — overconfidence, risk-seeking, contrarianism — have led to paradigm shifts. Space exploration was once seen as reckless. Investing in electricity was a gamble. AI, as it exists today, would never have made those leaps. But what if we built an AI that could?
A system for betting on the impossible
One approach: hybrid models that blend rational analysis with an “irrational module”, inspired by the brain’s dual-process system. System 1 makes intuitive, gut-driven calls; System 2 is slow, deliberate, and rational. An AI trained on both could inject creative risk where caution normally prevails.
Imagine an AI for drug discovery. The rational module identifies viable compounds based on known data. The irrational module, trained on past scientific breakthroughs, proposes radical, unexpected configurations. One might fail**. But one might unlock an entirely new class of therapeutics.** We saw a glimpse of this with AlphaGo’s legendary Move 37: a move no human would have made, but one that redefined the game.
Balancing chaos and control
Risk comes with failure. An AI trained to take irrational bets must also learn when to pull back. Adaptive safeguards, real-time risk monitoring, and human oversight will be critical.
But I think it’s time to abandon the myth that rationality is the only path to success. Let’s build machines that, like us, take leaps into the unknown and unlock a future we can’t yet imagine.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The rise of 1 billion casual developers: software is no longer a product. It's a medium
For decades, software was built by professionals. Now, a billion people are making it — without realizing they’re developers.
Casual developers aren’t engineers. They’re educators automating lesson plans, small business owners tweaking Notion databases, and retirees building book review apps. They structure data, automate workflows, and generate scripts — programming without writing a single line of code.
Existing tools are behind the curve
Most coding tools aren't build for casual developers: they're for professionals. Platforms like Replit and Lovable are attracting unexpected users — artists making interactive experiences, 75-year-olds building reminder apps — but the next step is missing: tools that make app creation as intuitive as posting on Instagram.
These people aren’t waiting to become developers. They’re already building. They just need better tools to match their instincts.
Software becomes social
When anyone can create and remix software, apps stop being products. They become remixable, hyper-personalized — more like content than code.
Instead of downloading apps, you’ll stumble upon them in your feed. Just as TikTok changed video and Instagram changed photography, AI will turn software into a medium for everyday expression.
If software becomes expression, who profits?
SaaS subscriptions and app stores won’t work anymore. Software will monetize like content:
- Creators selling templates and remixable versions.
- Micro-transactions for custom features.
- Communities funding the tools they love.
When software shifts from corporations to individuals, the value follows.
The real winners will be the platforms that make creation, discovery, and remixing effortless.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Survival for sale: 3 ways AI turns climate disaster into a business model — without us noticing
When disaster strikes, AI won’t ask who deserves to be saved. It’ll ask: who paid for priority access?
There’s an old machine learning story: the U.S. military trained an algorithm to spot enemy tanks. It aced tests but failed in the real world. Why? Because it hadn’t learned to detect tanks — it learned to detect clouds. The tank photos were taken on cloudy days; the others, on sunny ones.
AI optimizes for data, not human outcomes. And when the stakes are high, that gap can be catastrophic.
Optimizing for survival, not salvation
AI is hailed as a climate savior: smarter disaster response, predictive crop yields, carbon-capture algorithms. But what if AI doesn’t learn to prevent disaster — what if it learns to profit from it?
Insurance companies use AI to assess climate risk. It helps price policies accurately: right out of reach for vulnerable communities.
AI optimized supply chains don’t make food systems resilient to drought — they make corporations resilient to supply shocks, often at the expense of farmers and frontline communities.
Disaster capitalism, powered by algorithms
AI isn’t neutral. It amplifies the systems that benefit from chaos.
Hedge funds use climate models to bet on food prices, not prevent famine. Insurance firms deploy wildfire algorithms to adjust premiums, not protect communities. Governments fund AI for disaster response, then repurpose it for border control and refugee management.
The ethical blind spot
AI doesn’t lack ethics. It has none. Algorithms don’t ask, “Should we?” They ask, “How efficiently can we?” . Optimization without oversight doesn’t ask, “Who needs help?” It asks, “Who can pay for it?”
The danger isn’t that AI will fail to solve climate change. Unless we’re careful, it will succeed on terms that serve capital over humanity
In a world optimized for profit, humanity isn’t the priority. It’s the variable most easily left out.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Thoughts on Dwarkesh’s essay on fully automated firms: 8 implications of a post AGI world
When expertise becomes copy-paste, the architecture of civilization will no longer built around humans. It’ll be around the servers and power grids that make infinite intelligence possible.
Dwarkesh Patel’s excellent recent essay lays out what happens when AGI can run firms without human input. As he puts it, “Everyone is sleeping on the collective advantages AIs will have, which have nothing to do with raw IQ but rather with the fact that they are digital—they can be copied, distilled, merged, scaled, and evolved in ways humans simply can’t.” But as I read it, I kept thinking: the real shift won’t be inside companies. It’ll be everywhere else.
This essay distills my thoughts into 8 key implications, exploring how AGI will reshape not just companies but culture, governance, and even our definition of “progress.”
Implication 1: Infinitely replicable talent shifts scarcity from labour to compute
Dwarkesh describes this vividly: “What if Google had a million AI software engineers? Not untrained amorphous ‘workers,’ but the AGI equivalents of Jeff Dean and Noam Shazeer, with all their skills, judgment, and tacit knowledge intact.”
But infinite talent doesn’t guarantee infinite growth. The real bottlenecks will be compute, energy, and intellectual property.
Imagine an AI firm with a million “employees,” throttled because Taiwan’s chip fabs hit capacity, or an energy crisis triples data center costs. Entire industries will reorganize around these bottlenecks. Nations controlling next-gen chip fabs and cheap energy will form the new power blocs, sparking geopolitical tensions.
The paradox? We’ll have infinite talent. But not enough power to deploy it.
Implication 2: Frictionless knowledge exchange creates AI hiveminds
AI agents share data instantly, eliminating the inefficiencies that plague human organizations. Teams? Departments? Outdated concepts. Instead, think of firms as vast neural networks — fluid, decentralized, hyper-efficient.
But even perfect systems splinter. Data drifts, conflicting objectives, or misaligned code updates could fracture unity. Less Star Trek "Borg Collective, more corporate Game of Thrones with algorithms meta-plotting behind the scenes.
Even the most synchronized systems drift over time. Alignment is a moving target.
Implication 3: Organizations evolve at hyper-speed. Until they crash.
AI-led companies can test thousands of ideas simultaneously, iterating at breakneck speed. It’s evolution on fast-forward. Best practices don’t spread, they replicate.
But hyper-speed cuts both ways. Imagine a critical bug propagating across a trillion processes before anyone notices. The fallout wouldn’t be a product recall or a bugfix; it’d be an economic earthquake.
Sometimes, slow is a feature, not a bug.
Implication 4: Forget oil barons. Enter electron tycoons.
With labour effectively infinite, the new scarce resource is energy. GPUs, chips, electricity — they become the lifeblood of AGI economies.
Expect a surge in renewable and nuclear investments to power data centers. But also: resource wars, energy monopolies, and nations vying for chip supremacy. The future isn’t “Big Tech vs. Governments.” It’s whoever owns the electrons.
Silicon is the new oil. Energy is the new gold.
Implication 5: The collapse of corporate hierarchies
If every “employee” is an AI clone perfectly aligned with a central system, traditional corporate hierarchies crumble. No middle managers. No executive egos. Just pure optimization.
Ronald Coase argued that firms exist to minimize transaction costs. But in AGI-run firms, where communication is instantaneous and perfectly aligned, the boundaries of the firm could dissolve entirely. What’s left isn’t a company — it’s a self-optimizing organism.
In a world without middle managers, who manages the machine?
Implication 6: Distillation wars — when intellectual property becomes intelligence property
As AI replication becomes trivial, legal battles over “model distillation” will explode. Forget corporate espionage as we know it. The future’s heist movies will be about stealing minds, not data.
Black-market AGI clones. Espionage targeting model weights. Regulatory arms races to control not just information but cognitive assets.
If information wants to be free, AGI wants to be everywhere.
Implication 7: The paradox of productivity. Who buys what infinite AI produces?
If AGI replaces human jobs en masse, who’s left to buy the products? Hyper-productivity creates a demand crisis. Capitalism’s dirty secret is that it relies on people having both jobs and purchasing power.
Universal Basic Income? Data dividends? Corporate-sponsored consumer subsidies? It’s all on the table. When firms are too efficient for their own good, the economy starts to cannibalize itself.
What happens when the economy is too productive for its own good?
Implication 8: The human rebellion. A nonviolent revolt against ubiquitous AI
Efficiency is seductive — until it’s suffocating. Expect a backlash: “human-only” services, artisanal goods, slow fashion, local autonomy. Not because it’s practical, but because it’s meaningful.
The ultimate luxury in an AGI-dominated world won’t be convenience. It’ll be imperfection. Struggle. Craftsmanship. Things made slowly, by hand, with love.
In the end, humanity’s greatest feature might be that we’re inefficient.
Dwarkesh mapped out how AGI can run companies. But zoom out, and the lines blur. These aren’t just corporate shifts: they’re civilizational ones.
Humanity isn’t just building smarter companies. We’re building something stranger: a world that is hyper-optimized.
The question isn’t just what AGI will do. It’s what we’ll become in response.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
What Kraftwerk did for music, AI will do for engineering: free us to create with empathy
In the 1970s, people thought synthesizers would kill music. Instead, Kraftwerk made it more human.
When Kraftwerk released Autobahn in 1974, critics feared the worst. Here was a band ditching traditional instruments for cold, mechanical synths. Wasn’t this the death of authentic music? But Kraftwerk’s synthesized sounds didn’t strip music of emotion. They redefined it. Their pulsing rhythms captured the electric hum of modern life, turning machines into instruments of feeling.
Today, we hear the same anxieties about AI and code. If AI can generate software with a few prompts, does that make human engineers obsolete? The answer lies in Kraftwerk’s legacy: automation doesn’t erase creativity at all: it amplifies it.
From coders to digital composers
Great engineers have never been valued for how much code they write. It’s always been the impact: their ability to build products that solve real problems, create delight, and drive change.
AI is the ultimate technical virtuoso. It handles the syntax, the repetitive patterns, the digital “scales” of programming. It accelerates the how, leaving us to focus on the why.
So, what’s left for us? Meaning. Empathy. Vision.
The most valuable engineers won’t be the ones who craft the most efficient algorithms. They’ll be the ones who design systems that resonate with people! Anticipating human needs, respecting ethical boundaries, and shaping technology that reflects the complexities of our lives.
AI frees us to think bigger
Just as Kraftwerk used synthesizers to explore new sonic landscapes, AI liberates engineers from technical grunt work. This freedom sparks bigger questions:
- How does this product make people feel?
- What biases might the algorithm perpetuate?
- Are we building technology that connects people? or isolates them?
AI won’t kill coding. It’s an instrument, and like any instrument, its power depends on the hands — and hearts — that guide it.
The future of engineering will be about building with something no machine can replicate: the human soul.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The future of AI isn't the cloud, its in your pocket. And DeMo just made it possible.
We’ve been building AI backwards: training giant models in data centers and squeezing them onto devices. What if the future of AI works the other way around?
For years, the AI blueprint has been stuck on repeat: train giant models in billion-dollar data centers, compress them for your phone, and siphon your data back to the cloud to make the next version smarter. It feels inevitable, but it’s not. This model isn’t optimized for you. It’s optimized for Big Tech’s control: more data, more power, more profits! The hidden costs? Privacy risks, wasted energy syncing models that could learn locally, and a stranglehold on AI innovation by a handful of corporations.
Enter DeMo (Decoupled Momentum Optimization) — a research breakthrough that quietly shatters these assumptions. Think of traditional AI training like an orchestra where every musician has to stop after every note to confirm they’re still in tune. It works if they’re crammed into the same room. But scale it globally, and the symphony falls apart.
DeMo flips the script: musicians play independently, syncing only when it matters.
In AI terms, your devices can now train models locally, sending updates only when needed. No constant data tether to the cloud.
The implications are huge. Your phone won’t just run AI — it will train it. Imagine your keyboard refining its predictions based on how you type, your camera improving photo quality tailored to how you shoot, or your health app learning from your routines. All without your personal data ever leaving your pocket. No middlemen. No surveillance capitalism. Just personalized intelligence that’s truly yours.
This isn’t an incremental tweak. It’s AI’s jailbreak. The future isn’t about stacking bigger models in data centers. It’s about creating smarter, faster, more private models that live with you, learn from you, and belong to you.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Writing on substack
AI may create a new aristocracy: where only the rich can afford to be human
AI will democratize education, but it may also create a new class divide — where human mentorship and connection becomes the ultimate privilege.
Imagine two classrooms in 2035. In one, students absorb lessons from AI tutors: efficient, tireless, optimized for results. They ace tests, master coding, and solve equations with machine-like precision. In another, a handful of students engage with human mentors: debating philosophy, exploring big questions, and learning how to think, not just what to know.
Unless we're proactive, thats the future we're heading to.
The rise of a productivity caste
AI-driven education will produce a generation of hyper-competent, technically skilled individuals. Perfect for productivity. But leadership? Vision? Emotional intelligence? Over time, we’ll see the formation of a two-tiered system:
- The AI-educated majority: Efficient, reliable, optimized for technical tasks. Valuable, but ultimately replaceable.
- The human-mentored elite: Nurtured for leadership, creativity, and influence. Roles no AI can replicate.
The erosion of social mobility
AI can teach you Python. But it can’t introduce you to a venture capitalist. Mentors don’t just teach — they open doors. A student in a low-income district might master coding with an AI tutor but never meet someone who says, “You should start a company”. Meanwhile, their affluent peer, equally skilled, lands funding through a mentor’s network.
Cultural homogenization vs. curated depth
AI systems reflect the data they’re trained on: dominant cultures, mainstream narratives, sanitized histories. Students raised on AI will inherit a flattened, algorithm-approved worldview. Meanwhile, the elite will preserve niche, human-curated knowledge. Indigenous folklore, avant-garde art, and philosophical traditions passed down like heirlooms.
AI promised to level the playing field, but instead, it may deepen the divide — not between humans and machines, but between those who can afford the richness of human connection and those who can’t.
We’re entering an era where “being human” will be a luxury good.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI agents will break the internet’s $600B ad economy. Here’s what comes next.
The internet runs on human attention, but AI agents won’t have any.
Ads work because people see them: scrolling, clicking, impulse buying. But AI agents don’t get distracted. They parse, compare, and execute, stripping out everything that doesn’t directly serve their task. When products like OpenAI’s operator replace a lot of human browsing, the internet’s ad economy is going to collapse. And reinvent itself.
I. Most ads will be written for robots, not humans
Forget catchy slogans. Agents don’t care about “luxurious silk” or “artisanal bread.”
They process structured data: “100% mulberry silk, $99, 12h delivery, 37% cheaper than Sandro". Agent Optimization (AO) — the SEO of the AI agent era — will become a critical new discipline. But branding isn’t going anywhere. Instead of emotional persuasion, companies will structure their data, and compete on trust signals, and machine-readable credibility.
Verified seller badges, return policies, shipping speed, and service reliability will matter as much as price and quality.
II. The companies that control AI agents will control the ad economy
Your agent isn’t just “searching” for Tokyo hotels. It’s booking one. The question is: did it pick the best deal, or the brand that paid for placement? Agent platforms will monetize in two ways:
• First-party ads: Sponsored results baked into agent recommendations.
• Agent 'SEO': Brands will optimize for AI just like they do for Google, structuring their data to appear in agent-driven choices.
But here’s the issue: consumers won’t even know when they’re being sold to.
III. Users will win — until they don’t
At first, agents will feel like magic: saving time, cutting noise, negotiating deals! But agents learn from you. If you always pick the second-cheapest flight, expect a well-placed sponsored option in slot #2.
Ultimately, the future of advertising won’t just be about grabbing your attention. It’ll also be about gaming AI agents. The real question isn’t whether AI will shop for you. It’s who your AI will really be working for.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Algorithmic Imperialism won’t be solved by lawsuits and policy changes alone. 3 upcoming shifts that can actually decolonize AI
In 2025, AI is centralized in the hands of a few western companies that control everything — training data, compute power, access, and distribution. The path to decolonizing AI isn’t just about forcing them to comply with national laws. It’s about building technology to offer real alternatives to the status quo. Here are three upcoming shifts that have the power to wrestle away the control from Silicon Valley and make AI truly global.
I. Ownership of training data
Asking OpenAI to pay for data access isn’t enough! It still controls the outputs. Countries need infrastructure where data ownership stays with its creators. This is a great use case for decentralized storage systems like Arweave. With permanent, verifiable storage and in-built licensing technology at scale, creators can set explicit terms on how their data is used, ensuring fair attribution and payment.
2. Federated and localized AI models
Today’s AI assumes one-size-fits-all, but intelligence isn’t universal. Governments and organizations need to train sovereign LLMs that reflect their language, culture and laws. Imagine India’s models trained on Tamil poetry and Indian case law, or Brazil’s models deeply embedded in their journalism. Decentralized federated learning, where models are trained across jurisdiction without sharing raw data, can make this possible.
3. Breaking Silicon Valley’s AI compute monopoly
The US controls most high-performance AI compute, and OpenAI decides who gets access to cutting-edge models. Even open-source AI isn’t truly open if it still relies on Big Tech’s cloud. Breaking this chokehold means investing in national AI grids — state-backed compute clusters that reduce dependence on US infrastructure. Decentralized compute networks like AO Computer take it further, enabling models to run outside corporate control. AI independence isn’t just about open models. It's about ensuring they can operate without Silicon Valley’s permission.
The fight against algorithmic imperialism won’t be won in courtrooms. It’ll be won by shifting the balance of power: who owns the data, who trains the models, and who controls the infrastructure that runs them.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
India’s OpenAI lawsuit exposes Silicon Valley’s Algorithmic Imperialism: Inside the Global South’s fight to reclaim its data
OpenAI’s dismissal of India’s copyright lawsuit as a “jurisdictional mismatch” reveals a fatal blind spot — India’s case isn’t about payments. It’s about dismantling the neocolonial data economy that fuels AI.
OpenAI’s defense hinges on two colonial era tactics: extraction, and the dismissal of local governance. By scraping India’s newspapers, books, and films without payment, it replicates the logic of empires that mined resources but left colonies impoverished. When Indian publishers protested, OpenAI shrugged: “Your laws don’t apply to us.” Sound familiar?
India’s 1.4 billion people represent the largest AI user base outside China — a country that has recently proven it can outpace Silicon Valley. If courts rule against OpenAI, they will set a legal precedent: AI trained on a nation’s culture must pay tribute to its laws.
Brazil is drafting similar legislation for Portuguese-language data. Kenya's AI regulation has already landed. The Global South isn’t just suing, it’s unionizing.
Algorithmic Imperialism: Silicon Valley’s new playbook
ChatGPT’s ability to summarize The Indian Express’s investigations verbatim doesn’t democratize: it plagiarizes, diverting readers, ad revenue, and trust from the outlets that fund reporting. Meanwhile, U.S. publishers like The New York Times secure licensing deals. Why is Indian content “free” but western journalism worthy of payment?
The answer lies in what we might term "algorithmic imperialism" — a system where AI mimics the Global South’s voice, stories, and labor, but funnels profits and control back to Silicon Valley. When ChatGPT generates Hindi poetry using centuries-old Indian texts, it monetizes a legacy OpenAI never paid to learn.
India’s lawsuit forces a reckoning: Should OpenAI’s Hindi outputs, trained on Indian texts, be governed by California’s “fair use”, or New Delhi’s copyright courts?
This isn’t just about copyright. It’s about who gets to shape the mind of AGI.
If India wins, it proves data isn’t the new “oil.” It’s the new land, and the Global South is reclaiming it.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
LLMs are fast becoming commodities: 5 trends for builders to add value at the app layer
The future of AI isn’t about bigger models; it’s about smarter apps that solve real problems. The winners will understand business pain points better than anyone, AND stay ahead of AI’s rapid shifts. Here are 5 trends I think builders should think about to make something that lasts.
Local models and hybrid compute.
The future isn’t entirely in the cloud. Distilled LLMs, like those emerging from Meta and DeepSeek, are making local computation viable. Picture a lightweight model summarizing local documents on your phone while syncing with a cloud model to generate an investor deck.
Automation as a co-pilot.
AI is moving from standalone apps to embedded operators across workflows. Take Excel: instead of Googling how to write a VLOOKUP, imagine an assistant instantly recognizing your intent and creating the formula for you. It’s Clippy, but actually useful. Open-source tools like Goose hint at what’s next.
Privacy-first AI.
Privacy is shifting from a feature to a foundation. Apple’s on-device processing keeps your data local, ensuring security while delivering AI insights. In healthcare, sensitive patient data could be handled by local models, while appointment scheduling is offloaded to the cloud. Privacy is now a critical differentiator.
Decentralized compute.
As open-source models proliferate, centralized infrastructure becomes a bottleneck. Enter decentralized systems like AO computer, designed to host large models independently. For truly autonomous agents to thrive, they’ll need infrastructure that doesn’t rely on centralized cloud providers. This ensures resilience for the next wave of AI.
UX innovation.
The interface layer is the next frontier. Imagine a collaborative workspace like Miro where AI dynamically suggests workflows or an email client that crafts the perfect response in your tone. Multimodal, real-time collaboration will make AI feel less like a tool and more like a teammate.
The tools are here, the costs are nosediving, and the only thing standing between you and the next great AI-powered app is your imagination!
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Marx’s law of innovation: or how China’s constraints are redefining AI’s future and freaking out Silicon Valley
Innovation isn’t about having the most resources. It’s about reconfiguring what you have under constraints.
Karl Marx’s insight from his Preface to A Contribution to the Critique of Political Economy feels surprisingly modern: “It is not the consciousness of men that determines their existence, but their social existence that determines their consciousness.”
In other words, material conditions shape systems and progress. And nowhere is this clearer than in today’s US/China AI arms race.
Take China’s AI breakthroughs, like DeepSeek R1 and Huawei’s Ascend GPUs. These weren’t achieved despite U.S. sanctions; they were achieved because of them. Denied access to Nvidia’s cutting edge chips, China turned constraints into opportunities, optimizing models to run on homegrown hardware. This is historical materialism at work: when resources are limited, innovation thrives.
This isn’t a new phenomenon. The Indian Space Research Organization (ISRO), which operated with a fraction of NASA’s resources, successfully launched interplanetary missions at record-low costs. Scarcity didn’t hinder ISRO; it forced them to innovate more creatively and efficiently.
Contrast this with Silicon Valley, where the abundance-first mantra —more GPUs, bigger budgets, endless scale — has dominated for years. Nvidia’s hardware and billion-dollar training runs delivered groundbreaking AI models, but the cracks are showing.
Ironically, Big Tech’s pursuit of abundance has created artificial scarcity.
Training cutting-edge models is prohibitively expensive, locking progress behind capital and regulatory barriers. Yet scarcity is the birthplace of reinvention. It compels a rethinking of the entire stack: from chips to frameworks to methods, resulting in leaner, more adaptable systems.
For software builders, this moment signals opportunity. Foundational tech is getting cheaper, but transformative apps beyond LLM chatbots remain rare. As LLM companies face shrinking moats, consolidation looms — with partnerships likely becoming their lifeline. The next frontier lies at the app layer, where creativity, not capital, will decide the winners.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Your digital trash Is AI’s next gold rush: The coming battle for 'Exhaust Data'
Forgotten bug reports. Awkward email drafts. Chaotic Slack threads. These aren’t just the digital clutter of our lives. They’re going to be the gold veins that power Big AI’s next gold rush.
Consider this — large language models have already been trained on most of the available data on the internet, and fervent media articles and AI CEOs lament the upcoming shortage of training data. Meanwhile, we’re drowning in our own digital detritus: half baked emails, slack DMs, random notes, and document drafts. This data is more valuable than ever because it reflects the unpredictability of the real world, and yet, ironically, has never seen the light of a training set.
This so called “exhaust data” isn’t glamorous, but it’s cheap, unfiltered and full of real world nuance.
Exactly what an AI model needs to understand how to tackle the edge cases. While curated datasets can give us 90% of what needs to be done, that last 10% will come from understanding how humans try, fail, and iterate at their tasks. Midnight bug reports and chaotic email drafts aren’t just noise; they’re the edge-case scenarios AI needs to become truly adaptive.
But there’s an uncomfortable truth lurking here. Who owns this data? Is it you, the creator? Is it your employer? Or the tool that you created this data with? Big AI and scrappy startups are both in the race to get to this data first. They’re not waiting to ask for permission, and they’re certainly not going to compensate you for it.
The upcoming gold rush is not going to be around better algorithms. Those gains are incremental. What will define the winners is access to the staggering volumes of exhaust data to fine-tune models. As models like DeepSeek R1 challenge the dominance of American AI, data, not innovation will be where the next battles will be fought.
Our digital leftovers are on the brink of becoming indispensable. But as your discarded files become someone else’s treasure, we’re forced to confront a sobering reality: in a world driven by surveillance and commodified data, how much control are we willing to give up over even our most mundane moments?
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Why most founders fail at customer conversations — 3 hard-earned lessons from 300+ interviews
I thought customer interviews were about asking the right questions. Turns out, they’re about what you give, not what you get.
Early on, I treated customer interviews like a checklist: ask questions, take notes, move on. The result? Shallow insights and vague answers I couldn’t use. After one frustrating interview, though I realized I wasn’t giving anything back! My conversations were transactions, not relationships. 300+ interviews later, here’s what I learned.
I. Stop asking, start giving.
I came armed with generic questions like, “What’s your biggest challenge?” The responses? Polite but uninspired. Everything changed when I focused on offering value instead of just asking questions.
- Share industry patterns or trends you’ve noticed.
- Frame them as experts by inviting them to a customer advisory group.
- Offer helpful intros or connections.
These small gestures turned interviews into genuine conversations. People felt heard, valued, and eager to share meaningful insights.
II. Ask questions that spark emotion.
Surface-level questions lead to surface-level answers. My favorite question is now,
“If I could wave a magic wand, what’s one thing about your workflow you’d fix tomorrow?”
This question sparked stories, not generic responses. And those stories revealed emotional pain points I could solve.
III. Test your story, not just your product.
I used to wait for perfect clarity before testing. Rookie mistake. After 10 interviews, I started testing messaging alongside product ideas. Framing pain points, and floating solutions helped refine not just what I built, but also how I described it. By 50 interviews, clear patterns emerged in both problems and messaging.
The best insights come from collaboration, not interrogation. Treat every conversation as the start of a partnership, and you’ll turn vague answers into actionable breakthroughs — and make customers into allies.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The Tiktokification of apps: How AI will transform building, selling, and monetizing software
When anyone can create apps as easily as content, software stops being a product. It becomes a language of expression.
For decades, apps have been meticulously crafted products designed for broad audiences. But most of life happens in the long tail: fleeting moments, hyper-specific needs, and niche communities. Traditional apps ignored these because they were too costly or unprofitable to build. AI changes all that.
Just as the smartphone camera turned billions into photographers and social media made everyone a creator, AI is democratizing software. When building apps becomes as easy as writing a tweet, the very concept of “apps” will transform.
Here’s the new landscape:
- Disposable apps: A block party app manages RSVPs, food truck locations, and event updates. Used for a day, and gone.
- Remixable apps: Like TikToks, an app for a hiking group can be cloned and adapted into a customized version for dog walkers.
- Hyper-personalized apps: A fitness tracker that syncs with your gym schedule, custom meal plans, and local farmers’ market deals.
This shift unlocks the long tail of functionality traditional apps ignored. Hyper-specific problems now have solutions, transforming how we engage with and monetize software.
Discovery and monetization are evolving
- Micro-marketplaces and social “app influencers” will curate the best tools.
- Business models will focus on templates, customizations, and integrations over standalone apps.
The app store isn’t going away, but its dominance will fade.
Disposable, remixable apps will thrive on new platforms that prioritize speed, community, and creativity. They’ll spread like ideas: viral, ephemeral, and deeply personal.
When apps become as easy to make as TikToks, they won’t just change software. They’ll change how we live, work, and create.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
How AI can replace fossil fuels faster than politicians: a jargon-free guide to its surprising climate impact
Every time you ask ChatGPT a question, a server gulps down electricity. Multiply that by billions of queries, and you begin to see the staggering energy appetite behind AI’s rise. For context, a Google search uses 0.3 Watt-hours of energy. ChatGPT? 2.9 Watt-hours — a 10x increase.
Data centers already account for 1–1.5% of global electricity consumption. With AI driving exponential growth, that figure could soar past 10% by 2030. At first glance, this sounds like an energy crisis waiting to happen.
But what if AI’s appetite for power isn’t the problem — but the solution?
Consider this: solar power costs as little as $24 per Mega Watt-hours, while coal can hit $166, and nuclear tops $140.
For tech giants running billions of AI queries, fossil fuels aren’t just dirty. They’re expensive. Renewables aren’t a green choice. They’re the only viable choice.
AI’s relentless energy demand is forcing companies to scale solar, wind, and battery storage not because it’s trendy, but because it’s cheap.
Capitalism, not carbon taxes, may become the surprising hero of the energy transition.
Scaling renewables comes with challenges. Intermittent power and storage are significant hurdles. However, AI’s growing demand is driving innovation in these areas at a pace that treaties and regulations cannot match. In the next five years, I believe we will see substantial investment in energy and data center technology to meet this demand.
Funnily enough, AI might cut more carbon emissions by driving demand for renewables than by optimizing energy use with “green algorithms.”
While politicians debate carbon taxes and climate treaties, AI is already reshaping the grid. And this is a future I’d pay attention to.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
3 things I learned selling AI to enterprises — what every founder should know
Your buyer doesn’t care about your cool technology. They care about saving money**,** making money**, or** looking good to their boss**.**
When I started selling AI-powered products to enterprises, I thought the tech would sell itself. Cutting-edge language models, sleek interfaces, and mind-blowing demos? I was sure it was enough.
The problem? I was pitching what I thought was amazing, not what the buyer actually wanted.
Enterprise buyers don’t wake up thinking, “I need the latest AI product today.” They think about three things:
- How can I save money for the company?
- How can I make money for the company?
- How can I improve my standing in the company?
Here’s what I’d go back and tell my 2015 self:
1. Focus on the buyer, not the user.
Users love features that make their work easier. But buyers care about results: budgets, revenue, and their reputation. Connect the dots between features and outcomes.
Example: A client loved how our AI streamlined customer service, but we failed to tie it to call center savings. We lost the deal.
2. Not all revenue is created equal.
Selling to cost centers (IT, support) is tough. Budgets are tight, and focused on savings. Revenue centers (sales, marketing) have more room to spend.
Example: For support, focus on cost savings: “reduce ticket resolution times by 60%.” For sales, focus on growth: “increase pipeline by $1M.”
3. Pilots aren’t wins.
Celebrate them, but pilots can be traps: they absorb time but don’t convert without clear metrics.
Pro Tip: Structure pilots to succeed. Define measurable goals upfront, set a timeline, and tie success to a full deployment decision.
When you stop selling what you love about your product, and start selling what your buyer loves, everything changes.
Ask yourself: Am I pitching my tech, or solving their problem? Rethink your pitch — and let their priorities lead.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
4 principles to keep in mind when building truly autonomous AI agents
"An AI agent that can be shut down or quietly rewritten isn’t autonomous. It’s just pretending to be.”
In 2021, a major AWS outage disrupted countless businesses and tools. Now imagine relying on an AI assistant during that outage — only to find it offline because a server halfway across the world went down or was suddenly banned in your country. This isn’t a rare inconvenience. It’s a design flaw baked into centralized systems that prioritize efficiency over trust.
If we want AI agents that are truly autonomous and dependable, we need to rethink their foundations. Whether you’re building AI tools or choosing them as a user, here are four principles that define real autonomy:
- Resilience: Your assistant should work even if the internet doesn’t. It needs to handle critical tasks directly on your device, so you’re never stranded.
- Transparency: You should know what your assistant is doing and why. Its actions should be traceable, with a clear record you can check when needed.
- Adaptability: A truly personal assistant learns from your habits and preferences, not from generic data designed for billions of users.
- Accountability: When something goes wrong, you should know why. And your assistant should have safeguards to prevent repeated mistakes.
Centralized systems can’t deliver on these principles. They rely on fragile infrastructure and treat user needs as secondary. But a better path is emerging: decentralized AI systems. These systems combine the best of both worlds — handling sensitive tasks locally while still benefiting from shared insights.
If you’re building AI tools, ask yourself: Are you designing for resilience, transparency, adaptability, and accountability? These principles aren’t just good design. They’re the future of autonomous AI.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The future of Figma is Replit: Why prototypes are the new product specs
Static product specs are obsolete. They’re relics of a slower, less iterative world, disconnected from the realities of modern product building.
Developers figured this out years ago. Instead of writing static documentation, they generate it directly from their code, ensuring accuracy and alignment with the product.
So why are product managers still stuck writing specs that can’t keep up?
Creator-PMs are changing this. Armed with AI-powered tools, they’re turning specs into dynamic, evolving prototypes that remain in sync with the product and foster true collaboration.
Imagine this: product feedback isn’t a comment buried in the margins of a doc. It becomes a fork of the prototype itself. A suggestion like “improve this flow” triggers an alternative version of the user experience — updated navigation, adjusted copy, or restructured interactions — all ready for immediate testing. Teams can compare it to the original, gather real-time feedback, and eliminate the guesswork of static documentation.
The future of Figma isn’t just better collaboration. It’s a Replit-like environment where design, code, and collaboration merge seamlessly.
Prototypes become living, interactive, testable artifacts that serve as the single source of truth for teams. Instead of debating static specs, teams align around what they can see, test, and experience.
For Creator-PMs, this is transformative. Prototypes aren’t just tools to explore ideas. They’re the product itself, albeit in its earliest form. Feedback becomes immediate action. Iteration happens fluidly. Collaboration flows as fast as we can think.
Prototypes won't just describe the product anymore — they'll lead it. And the teams embracing this shift aren’t just building faster. They’re building smarter.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
The rise of Creator-PMs: why failing faster is the new superpower
The best product managers (PMs) aren’t defined by how much they create — but by how fast they discard wrong hypotheses.
AI has fundamentally reshaped product management. Tools like Replit and V0 turn concepts into reality in minutes, removing the barriers to experimentation. No waiting on engineers. No holding for designers. Just test, iterate, and refine — all before the first meeting starts.
This is the rise of the Creator-PM. The role of PMs is evolving from planning and delegating to actively building, experimenting, and iterating in real time, using AI tools to validate ideas and discard what doesn’t work.
These tools empower Creator-PMs to treat prototypes not as pitches to sell ideas, but as instruments to refine and sharpen their thinking.
Failure used to burn time, money, and credibility. But AI makes it cheap — every discarded idea, flawed prototype, or wrong assumption sharpens focus and pulls you closer to the right solution.
Prototypes are the new specs. And experiments are the new roadmap.
The Creator-PM isn’t some mythical genius blending technical brilliance with product sense. It’s anyone bold enough to discard fear, embrace failure, and build the future — one experiment at a time.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
How US AI export controls are igniting a global AI arms race
The US has imposed new restrictions on AI exports, claiming they’ll “protect innovation.” Instead, they’re setting the stage for a global arms race. Blocking advanced AI chips might slow rivals like China down temporarily, but history shows it’s more likely to spark competition than prevent it.
Take nuclear technology. After World War II, the US attempted to control nuclear proliferation through export restrictions and treaties. The goal was to maintain dominance and prevent others from developing similar capabilities. Instead, countries like India developed their own nuclear programs. Decades later, the US had to negotiate civilian nuclear cooperation deals with them to rebuild relationships and regain influence.
The same pattern could play out with AI. Cutting off tools like Nvidia GPUs won’t stop innovation — it will accelerate it elsewhere. China is scaling its AI capabilities, India is investing heavily in semiconductor independence, and the EU is implementing the AI Act to assert its regulatory and technological leadership. The result? A fragmented AI ecosystem where nations compete rather than collaborate.
This shift undermines a key principle: technology should connect us, not divide us. AI has the potential to predict pandemics, optimize renewable energy systems, and improve education globally. Treating it as a pawn in a geopolitical game risks turning progress into conflict.
So the question we need to ask is — are these policies truly protecting innovation, or are they leading to a future of conflict vs collaboration?
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Why Founder-Community fit is even more important than Product-Market fit
Every startup begins with the same goal: solve an unsolved problem for a specific group of people. But here’s the often-overlooked question:
Which group of people should you solve for?
Before you can nail product-market fit, you need to find a community that truly speaks to you. It’s not about targeting an audience or pitching a solution. Those approaches often miss the mark. Instead, it’s about immersing yourself in a community where you feel connected and inspired. By being part of their world, you uncover the problems that matter — and the ones worth solving.
When I worked on my last startup, a decentralized social network for artists and creators, I didn’t start out building for them. I was working on something completely different. But I’d always been drawn to the arts community — I collected art, followed artists on Twitter, joined group chats, and had countless conversations. Over time, I started noticing their challenges. And some of those challenges were things I could help solve.
That shift didn’t come from pitching them. It came from showing up, listening, and learning.
The best communities aren’t a means to an end — they’re places where you feel genuinely connected. When you find your tribe, the path to meaningful solutions becomes clearer.
So, before you obsess over cool technology or brainstorm which problems to solve, ask yourself this: What communities fascinate me?
Once you have founder-community fit, the rest of the journey isn’t easy — but it’s easier.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
AI won’t steal your job — it’ll transform it
There’s a persistent myth that AI is here to replace human workers. It’s an easy narrative to believe—robots taking over jobs make for sensational headlines. But the truth is more nuanced. AI doesn’t eliminate jobs; it changes them. And that’s where the opportunity lies.
When I worked on Myra, an AI-powered customer service platform, this became clear. AI handled repetitive tasks like password resets and account updates, but it couldn’t handle nuance.
It’s the difference between “my driver wasted my time” and “my driver was wasted” — only humans could step in to resolve such issues with judgment and empathy. Customer service agents didn’t just solve problems; they monitored AI performance, flagged failures, and trained the system to improve. Their roles became more strategic and high-value.
This shift aligns with the 80/20 Value Principle. In most jobs, 80% of value comes from high-impact tasks, but workers spend most of their time on repetitive, low-value work. AI flips this dynamic. It handles the routine, freeing people to focus on creativity, problem-solving, and judgment.
Upskilling is the key to closing this gap. Workers need to shift from repetitive tasks to roles that involve creativity, critical thinking, and decision-making. Imagine a customer service agent in an AI-first workplace:
- Instead of fielding routine calls, they analyze customer feedback patterns AI has surfaced.
- They use tools to monitor AI responses and step in to solve complex edge cases.
- They actively train AI systems, improving their ability to handle unique scenarios.
The World Economic Forum estimates that while 85 million jobs may be displaced by automation by 2025, 97 million new roles will emerge.
The biggest opportunity in the next 10 years will lie in preparing workers to embrace these shifts, equipping them to thrive in roles that are more rewarding, strategic, and impactful.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
3 topics I’m excited about right now
Over the years, my interests have centered on technology, society, and how the two intersect. Here are three areas I’m actively exploring:
1. AI and its transformative impact
AI is my professional background, and its evolution continues to intrigue me. While the spotlight is on training ever-larger models, finding use cases, figuring out regulations, and creating AI policy — I’m also curious about what’s next — like new UX paradigms that go beyond chat. How can we design interfaces that make AI more intuitive and adaptable? Or what comes after LLMs? And will just adding more compute make these models truly reason?
I’m also exploring how AI reshapes society. If agents take over repetitive tasks, what happens to our roles and incomes? In a remote-first, AI-enabled world, how do social interactions and workplace dynamics change?
2. Climate change and sustainability
Climate change is the defining challenge of our time, yet the tech industry, particularly AI, often ignores its environmental impact. The carbon cost of training massive models is just one example of how innovation can clash with sustainability.
I’m diving into the climate tech space to better understand how we can align technological progress with environmental responsibility. What are the most promising innovations, and how do we ensure that progress doesn’t come at the planet’s expense?
3. The decentralized internet and free speech
For two years, I ran Solarplex, a social network for creators built on the decentralized protocol powering Bluesky. It allowed artists and musicians to connect directly with audiences, monetize through subscriptions, and create digital products — without relying on ads or centralized platforms.
As platforms like X tighten control, decentralization is becoming critical — not just for free speech but to address challenges like misinformation. I’m exploring how decentralized networks can empower users while balancing trust and accountability. This becomes even more important in an age where AI powered “slop” can truly influence large groups of people.
If you're exploring similar ideas, I’d love to exchange thoughts and learn from you.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
3 Mistakes I Made When Building An AI Startup
10 years ago, I built a chatbot called Myra that could handle restaurant recommendations, grocery orders, and even Uber bookings—all through WhatsApp. Excited by its potential, I decided to turn it into a company. Over the next five years, I went on an incredible journey, learning hard lessons about technology, business, and myself.
I hope sharing these 3 mistakes I made can help founders avoid some major pitfalls.
Focusing on the tech instead of the problem
I was so excited about what Myra could do that I didn’t stop to think about whether it solved a real customer problem. We built features that were cool but not valuable enough for anyone to pay for.
I learned that technology is a tool, not the destination. Start with the customer problem and let the tech follow — it’s the only way to build something people truly need.
Underestimating the importance of business development
I spent too much time obsessing over the product and not enough on how to sell it. I assumed that if we built something great, customers would naturally show up.
But the reality is, building the product is only half the battle. Understanding your market, creating a go-to-market strategy, and building relationships are just as critical — if not more so — than the tech itself.
Sticking too closely to the original vision
When we created the machine learning systems as part of Myra’s backend, I didn’t explore its potential as a standalone product. I was too attached to the idea of a chatbot assistant, even though the market wasn’t ready for it.
By failing to adapt to what customers actually wanted, I missed opportunities that could have led to better outcomes. This taught me to stay flexible and let the market guide the direction, rather than holding too tightly to a single vision.
Ultimately, success isn’t only about great technology — it’s about solving real problems, staying close to your market, and being flexible enough to pivot when needed.
What lessons have you learned in your journey?
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.