Optimizing Tool Selection for LLM Workflows: Differentiable Programming with PyTorch and DSPy
Update: Trended on Page 1 on HN for the whole weekend! Part 2 coming soon! Thanks for all the feedback. Hackernews discussion
How local, learnable routers can reduce token overhead, lower costs, and bring structure back to agentic workflows.
Modern agentic architectures rely heavily on chaining LLM calls. A typical pattern looks like:
- Use an LLM to decide which tool to invoke
- Call the tool (e.g. search, calculator, API)
- Use another LLM call to interpret the result and generate a final response
This structure is easy to reason about, simple to prototype, and generalizes well.
But it scales poorly.
Each LLM call incurs latency, cost, and token overhead. More subtly, it compounds context: every step includes not only the original query, but intermediate outputs and scratchpad logic from earlier prompts. This creates a growing burden on both inference and model performance.
The consequence is that most agent stacks are paying GPT-4 to do what amounts to classical control flow — tool selection — with no reuse, no abstraction, and no efficiency gains at scale.
The Alternative: Differentiable Routing
Instead of using an LLM to route between tools, we can model the decision as a trainable function. A differentiable controller learns tool selection from data — typically via reinforcement or supervised fine-tuning — and runs entirely outside the LLM.
The benefits are architectural:
- Local execution — avoids external API calls
- Determinism — removes stochastic sampling from routing
- Composability — integrates natively with PyTorch / DSPy pipelines
- Control — tool choice is explainable and debuggable
A minimal examples looks like this (PyTorch):
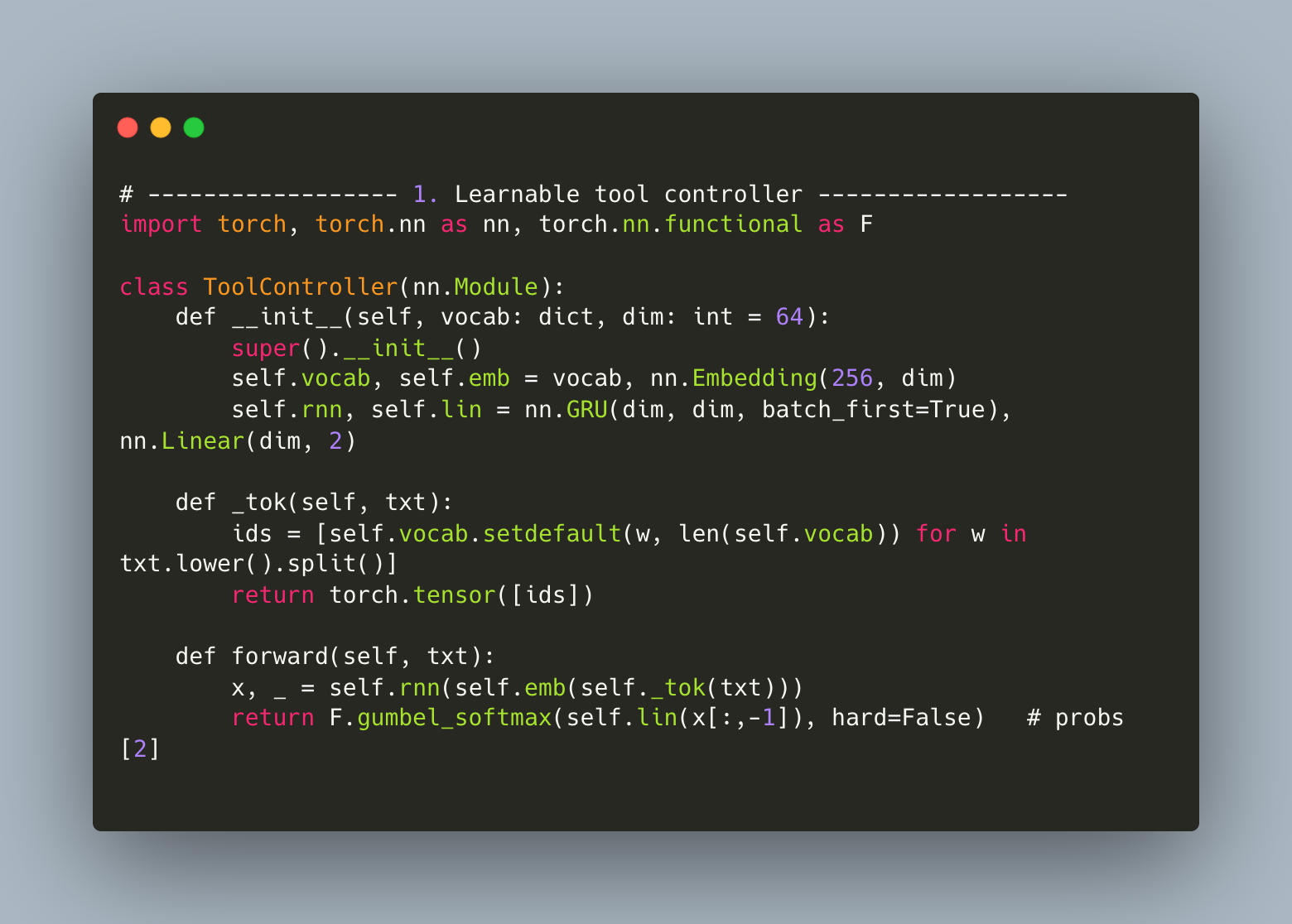
This is a simple 4-layer network: input is tokenized text; output is a softmax distribution over tools. Because it’s differentiable, you can backpropagate from downstream task reward and improve the router over time.
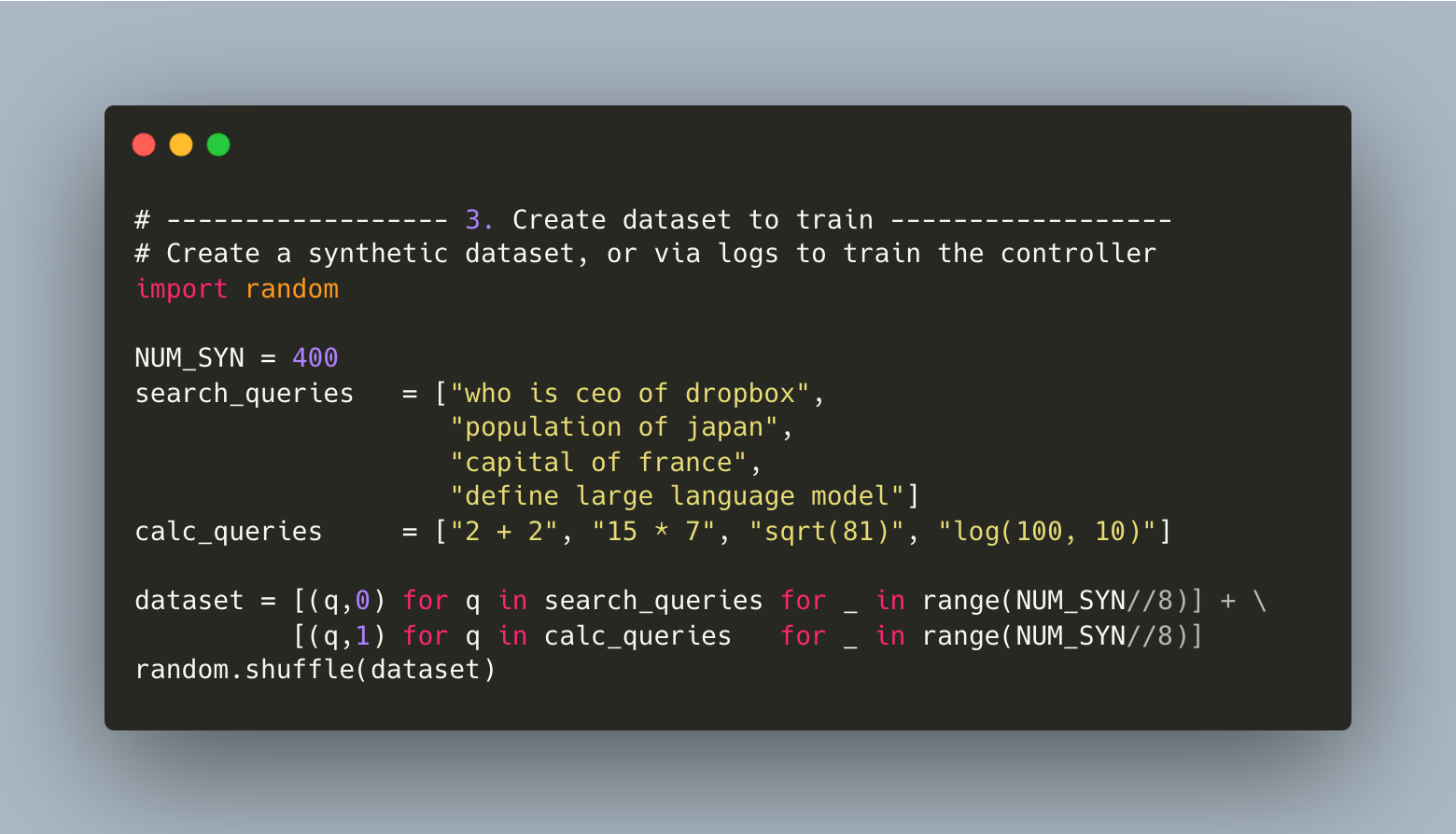
We can either get data from existing logs, or use GPT to create a synthetic dataset. (Our costs will be one time per tool controller, vs LLM calls for them in production).
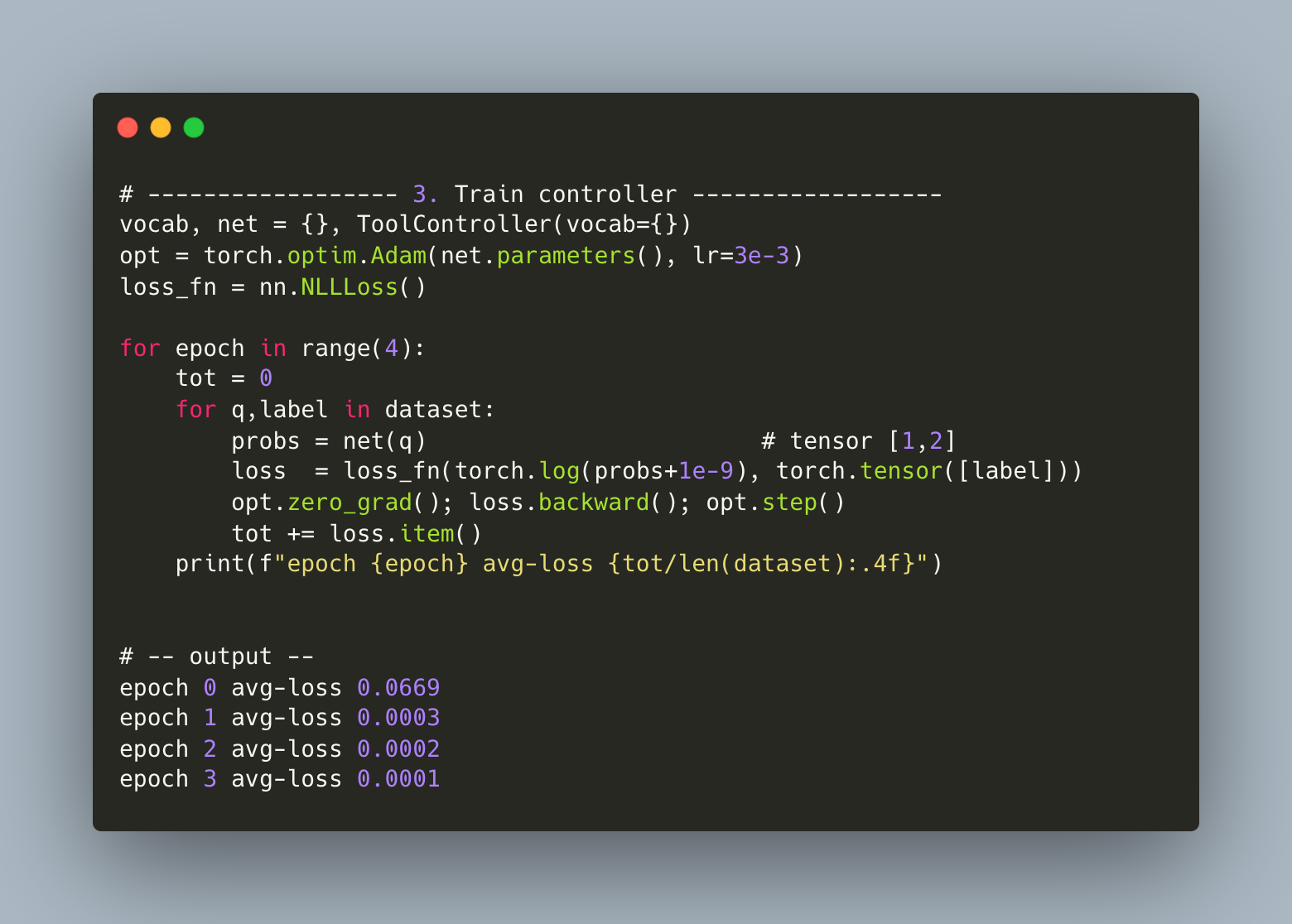
We use a simple Adam optimizer to train this simple controller.

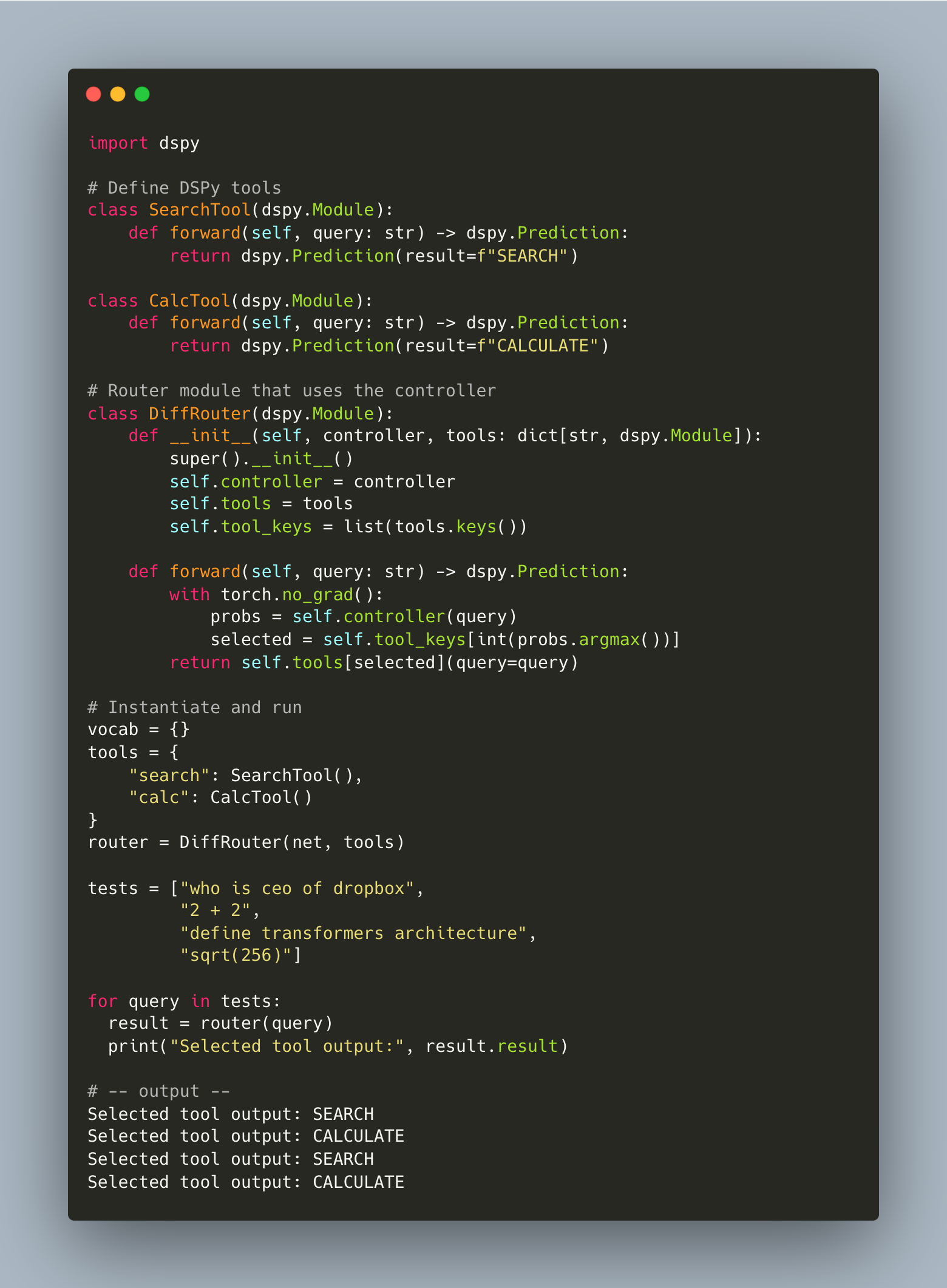
And finally, the demo!
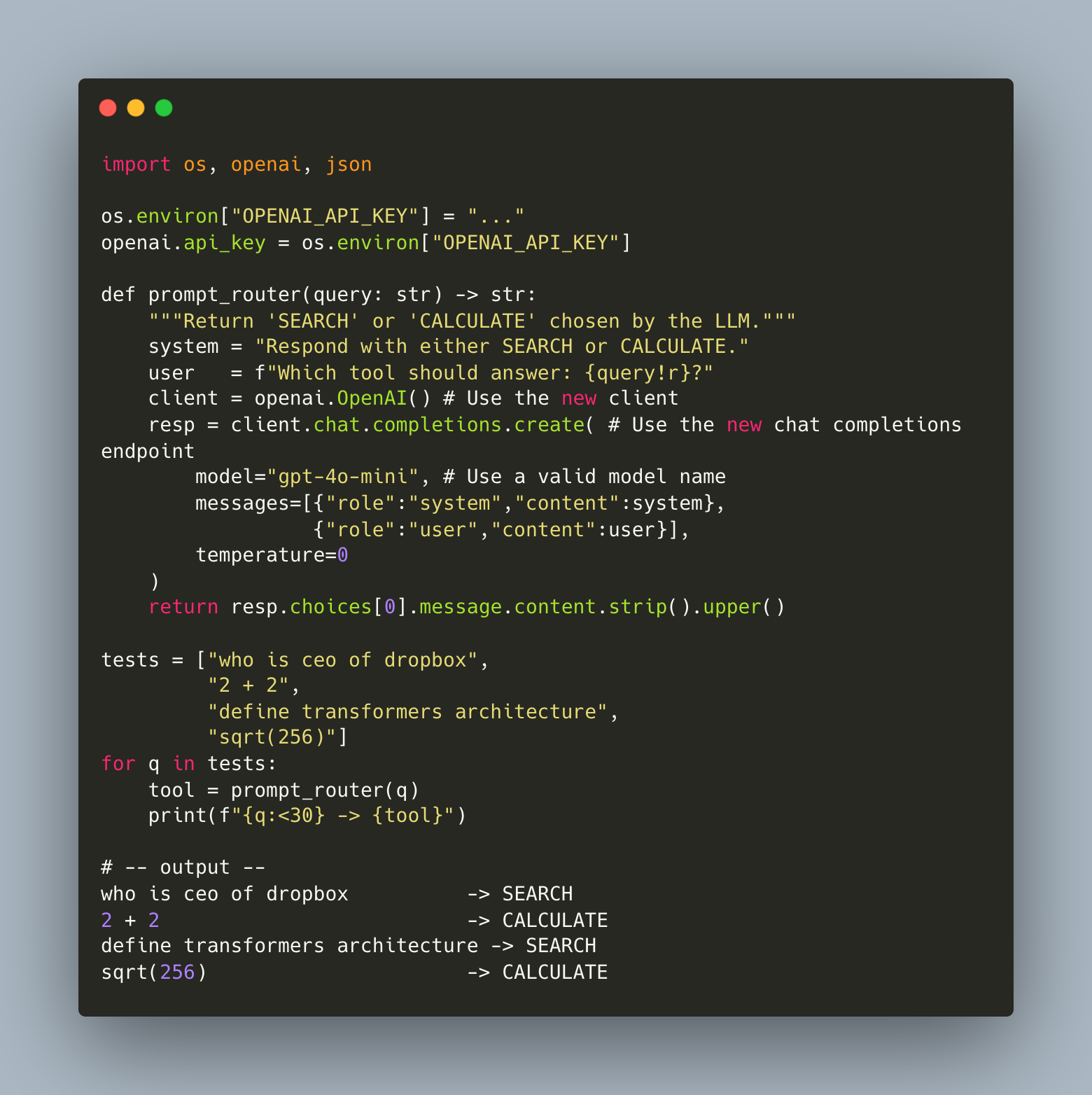
For completeness, this is how we’d do it via an LLM directly.
And as a bonus, here’s how you would integrate it into a DSPy Pipeline.
Context Growth and Model Degradation
Prompt-based planners incur a hidden penalty: context inflation.
Each new prompt must reintroduce the full conversation history, prior decisions, and any scratch output. The result is exponential growth in irrelevant tokens, particularly in multi-hop workflows.
This leads to:
- Token tax — redundant tokens sent repeatedly
- Truncation risk — long contexts hit model limits earlier
- Attention dilution — more tokens competing for limited compute
- Leakage — planner logic unintentionally affects final output
By contrast, a differentiable router operates entirely out-of-band. The only input to the final LLM call is the original query and the selected tool’s result. Context length is constant regardless of tool depth.

This architectural separation restores clarity to the final model call — reducing hallucinations, improving determinism, and reclaiming inference capacity for core reasoning.
Strategic Implications
The shift to differentiable routing mirrors a broader trend:
Separating declarative control logic from generative inference.
Current agentic systems blur this line. Tool selection is handled in the same modality — and often the same model — as natural language generation. This creates coupling where there should be composition.
Differentiable programming is one way to decouple the two:
- LLMs focus on generation and synthesis
- Lightweight neural modules handle routing, orchestration, and control
The result is a more modular, inspectable, and scalable architecture — one that avoids paying transformer inference costs for classical programming constructs.
Prompt Routing and Its Costs
To drive this home, lets consider a planner that routes queries between a search API and a calculator tool. Each query invokes:
- One LLM call to plan
- One LLM call to interpret the tool’s result
- One LLM call to generate the final answer
At GPT-4.1 prices (75 input / 75 output tokens per call), this costs:

A 3× reduction in cost per run — with larger savings as tool chains grow in complexity.
Conclusion
In early-stage workflows, LLM routing is fast to implement and flexible to extend. But at scale, it’s structurally inefficient — economically and architecturally.
Differentiable controllers offer an excellent alternative. They reduce cost, improve performance, and clarify model behavior. They mark a step toward LLM systems that look less like prompt chains — and more like programs.
--
--
Questions or feedback? @viksit on Twitter.
From Prompts to Programs: Why We Need a Compiler for LLMs
Early computing started with logic gates. We wrote in binary because we could reason about how bits flowed through circuits. As complexity grew, we invented assembly languages to abstract over machine code: still low-level, but easier to manage. Eventually we built high-level languages like C that let us describe intent, not instruction sequences.
Each jump in abstraction made us more productive. It let us build larger, more reliable systems without needing to hold every gate or register in our head.
We’re hitting the same point in LLM development.
LLMs today are logic gates — powerful, expressive, and composable. Prompts are our binary. You can wire together a few models, handcraft their inputs and outputs, and get something useful. But once you go beyond a handful of prompts — say, in agent systems, retrieval pipelines, evaluation layers — the complexity gets out of hand. It’s like writing an OS in raw assembly.
We need to move up the stack.
That’s what Selvedge is for: a compiler for LLM workflows. It’s a typed, declarative way to describe what you want, and a system that figures out how to make it happen.
Selvedge lets you define structured programs that wrap model calls, validate outputs, compose reasoning steps, and orchestrate everything with explicit control flow. The primitives are predictable. The types are enforced. The intermediate states are inspectable. It turns prompt soup into programs you can debug. The best part is — you barely write prompts.

Think of it like:
- C for LLMs: you define the logic, not the token stream
- SQL for cognition: you declare what you want, not how to traverse the model
We don’t think in prompts. We think in goals, logic, and flow. And the systems we’re building now — agents, copilots, assistants, autonomous processes — deserve tooling that reflects that.
Selvedge is an early step in that direction. A compiler for intent.
A language for AI native programs, not just prompts.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Three Futures for AI
We’re racing toward something. Whether it’s AGI or another false summit, the scale of what we’re building is hard to ignore.
There are only a few ways this plays out.
1. We scale current techniques to AGI.
The compute, energy, and coordination required are beyond any single country. power grids the size of Brazil, cooling towers louder than waterfalls. It becomes clear that no one country can do it alone. So we’re faced with a choice.
Do we come together and build it, or fight until one of us claims it for ourselves?
2. We invent a breakthrough.
Not scale. Just one singular leap out of a lab or a company or a garage. A chip, a model, a cooling trick. Suddenly, the gap between “close” and “there” disappears. Someone gets there first.
Do they share it? Or defend it like a weapon?
3. LLMs plateau.
They change everything, but stop short of general intelligence. We chase margins. Optimize workflows. The systems get smarter, but not general. Eventually the hype fades. Not because AI failed but because it settled into the tedium of obviousness.
A winter, not of research, but of imagination.
Two of these futures end in conflict. One in exhaustion. Only one asks us to act like a species.
We may not control what we discover. But we will decide how we respond.
I hope we choose well.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
When Software Starts To Listen
Most software today is basically deaf. You poke at it, and if you’re lucky, it does what you want. But it doesn’t listen. Not really. That’s about to change.
Say your product’s ad campaign just blew up. The VP wants a buy‑3‑get‑1‑free promotion online in the next ten minutes. In most companies, this would kick off a chain of escalation: tickets, grooming, prioritization, maybe a hotfix sprint. Everyone stressed. Nobody moving fast enough.
But imagine a different setup. You open a file called pricing.spec and type:
## flash_promo_may6_2025
if cart_items >= 4:
discount cheapest_item 100%
You hit publish. The storefront updates. You go back to your coffee.
This isn’t magic. It’s just what happens when the boundary between “spec” and “software” disappears. You stop writing instructions for other humans to implement, and start writing directly for the system.
That’s what I mean by software that listens.
It won’t show up everywhere at once. It’ll sneak in at the edges — inside bounded platforms that already own the stack. Salesforce. Shopify. Figma. Tools where the system already knows the schema, the constraints, the deploy surface. Once a model is embedded in that loop, a lot of the glue work goes away. The scaffolding becomes active.
You won’t need someone to translate what you want into what the machine can do. The machine will learn to speak human. And this breaks the org chart in interesting ways.
In the current world, building software is a game of telephone between PMs, engineers, and designers. Everyone has their domain, and communication is the hard part. But if the system listens — if it really listens — then you don’t need as many people repeating themselves.
You’re either:
- building with AI (apps),
- building AI itself (models), or
- building for AI (infra, safety, tooling).
That’s it. Everything else starts to look like overhead.
Jamie Zawinski once said every program grows until it can read email.
I’d guess that now, every serious app grows until it can read your mind.
We already see early versions of this: autocomplete, command palettes, prompt UIs. But the real magic happens when software predicts your intent before you articulate it. Not just filling in blanks — actually shaping the interface to fit your next move.
That’s coming. And when it does, the way we build things will start to invert.
Most people won’t notice at first. Architects will keep using their old CAD tools. Accountants will keep using Excel. Editors will keep using the timeline. But behind the scenes, those tools will start responding to natural language. They’ll adapt on the fly. They’ll let users patch over missing or new functionality without plugins or workarounds or other developers.
This is Excel macros for everything.
Except instead of writing brittle scripts, you’re just describing what you want — and the system figures out how to do it. Long-tail functionality stops being something you beg the vendor for. It becomes something you compose.
So where does that leave product managers? They don’t go away. But their work shifts up a level. They’re not writing tickets. They’re deciding,
- What the model should expose.
- What it should hide.
- What’s safe to extend.
- What breaks if someone gets too clever.
They define the primitives, set the defaults, and watch the feedback loops. Every model embedded in a product becomes a kind of UX researcher — logging friction, clustering hacks, surfacing gaps in capability.
Product becomes less about what gets built, and more about what can be built.
There are risks, of course. When software listens, it can also mishear. A stray prompt can mutate a database. A rogue extension can leak sensitive logic.
An LLM with too much power and not enough guardrails can wreck things in ways you won’t catch until it’s too late. This is where product and infra start to blur. Versioning, access control, audit trails — they’re not just technical features. They’re product decisions now. Governance becomes part of the interface.
The main thing to understand is this:
Software that listens collapses the distance between wanting and working**.**
Today, we build tools that people learn to use. Tomorrow, we’ll build systems that learn how people want to work.
And once that happens, the most valuable people in the loop will be the ones who can express intent clearly — and the ones who can shape how the system responds. If you’re not doing one of those two things, you’ll have to explain why you’re still in the room.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.
Prompt Engineering Is the New Assembly Language
There’s a belief circulating in AI circles right now that a cleverly written prompt is proprietary gold. That if you can coax the right output from a model, you’ve created something defensible.
I get the instinct. When something works, and nobody else seems to have figured it out yet, it feels like IP. But that feeling won’t last. Not because prompts aren’t useful, but because they’re legible, replicable, and quite disposable.
Prompts at their core are specs. They describe what you want a model to do, given a certain input and output shape. You write them in English, wire them into some UX or tooling, and if you’re lucky, the system does what you hoped it would.
But we’ve seen this pattern before. Every generation of software development starts with hand-tuned instructions, then moves toward abstraction and automation.
First, we wrote in binary. Then came assembly. Then C. Then Python. We built compilers and interpreters that took your vague intent and optimized it into something performant.
We’re about to hit the same inflection point with LLMs.
Tools like DSPy are already acting like early compilers, taking high-level intent and generating prompt graphs, optimizing them over time. With Selvedge, I’ve been exploring what it means to treat prompts not as text but as composable programs. Structured, typed, and abstracted from the model itself. The system handles the orchestration — which model, which format, which chain — based on the spec.
This is where prompts as a moat break down. If the compiler is doing the hard work, the prompt itself isn’t the moat. It’s a temporary interface, a layer that’ll be rewritten, tuned, or discarded automatically based on what the developer wants to do.
So what actually compounds?
Usage. Feedback loops. Distribution. You build defensibility by owning the layer where users express intent — not the syntax of that expression. The edge won’t come from the prompt itself, but from the infrastructure that improves with every interaction.
We’re moving from being prompt authors to becoming compiler designers. From crafting clever phrasing to building systems that know how to reason backward from a goal. The moat, then, isn’t the instruction at all. It’s the interface.
Prompts are just the starting point. The leverage lives in what you do after the user speaks.
--
If you have any questions or thoughts, don't hesitate to reach out. You can find me as @viksit on Twitter.